research
Advancing Search-Augmented Language Models

Introduction
Training frontier web search agents requires jointly optimizing multiple objectives: factual accuracy, trajectory efficiency, and user preference alignment. Yet improving any single dimension in isolation often degrades others: models trained solely for accuracy tend to overuse tools, while models optimized for brevity may sacrifice reliability or completeness. At Perplexity, neither outcome is acceptable.
This article describes Perplexity’s post-training pipeline for developing state-of-the-art web search agents based on open-source models. A key idea is that, in search-agent training, data curation and reward design must be co-designed: the data determines which behaviors are observable and verifiable, and the reward determines how those signals are translated into optimization signal. This principle motivates our two-stage pipeline: we first conduct a Supervised Fine-Tuning (SFT) warmup to initialize the policy model, and we then refine the policy model using Reinforcement Learning (RL) over a curated dataset and carefully designed rewards. This two-stage approach enables reliable gains in accuracy, efficiency, and response quality under production constraints.
We first describe our two-stage training pipeline (SFT → on-policy RL), followed by our RL training data construction, covering both verifiable search-agent QA and rubric-based general chat. We then present a composite reward design derived from this heterogeneous data setting, balancing quality and efficiency while mitigating reward hacking. Finally, we analyze training dynamics and benchmark results.
Two-Stage Training Pipeline
We adopt a two-stage post-training recipe: (i) SFT to establish deployment-critical behaviors such as guardrails (e.g., abstention), instruction following, and language consistency, and (ii) on-policy RL to improve search capability, including answer accuracy and tool-use efficiency, while preserving the behaviors from stage one.
Why two stages? Jointly optimizing search quality and deployment constraints within a single RL stage is difficult without compromising at least one objective. Empirically, RL-only training improves search performance but tends to underperform on deployment guardrails, while SFT improves compliance at the cost of search performance. Disentangling the objectives allows the SFT stage to address non-negotiable requirements first, after which RL can focus mainly on improving search capability.
SFT stage
We initialize from the Qwen3 family of models (Qwen3.5-122B-A10B and Qwen3.5-397B-A17B) (Yang et al., 2025, Qwen3.5 blogpost) and construct a two-component SFT mixture dataset targeting the deployment-critical behaviors described above, while preserving the base model's general search capability.
Preference-oriented examples. We curate instruction-following and style-focused examples targeting tone, language consistency, clarity, and formatting. These examples need not admit a unique ground truth; rather, they are selected to reflect product writing requirements and ensure stylistic consistency across diverse query types.
Production-format tool-use trajectories. Empirically, we find that SFT without careful dataset curation can substantially degrade the base model's search capability. To mitigate this, we sample queries and internal tasks across diverse interaction patterns (single-, two-, and multi-turn) and annotate them with our tool-calling harness.
RL stage
Starting from the SFT checkpoint, we apply on-policy RL to improve search accuracy and efficiency. We optimize the policy model using Group Relative Policy Optimization (GRPO) (Shao et al., 2024).
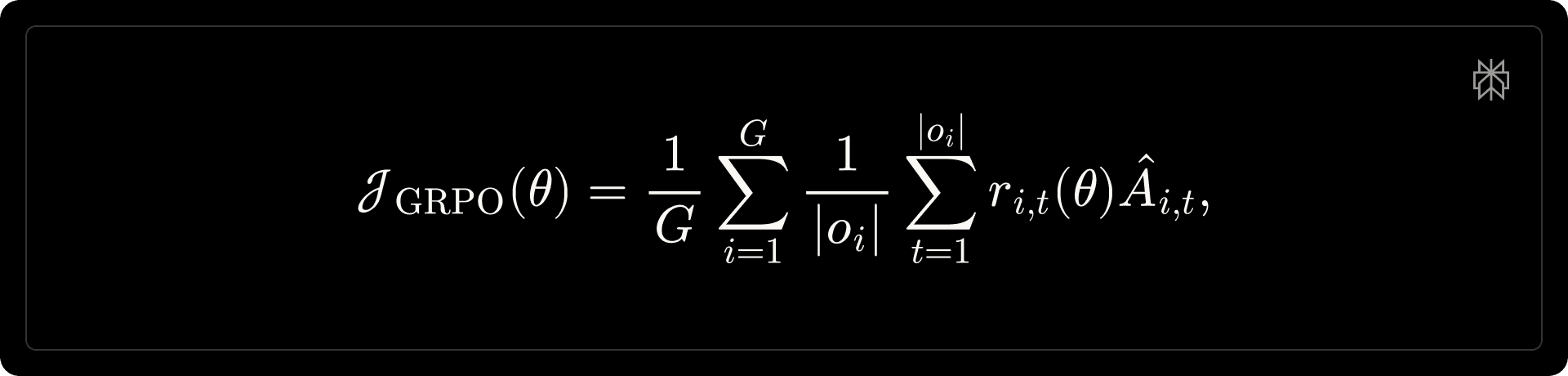
where [math]G[/math] is the size of the group, [math]o_{i}[/math] denotes the [math]i[/math]-th sampled output, and [math]\hat{A}_{i, t} = \hat{A}_{i}[/math] is the advantage. Reward design is detailed in the reward design section; in brief, we combine baseline correctness with preference-based and anchored efficiency shaping. Following prior work (Liu et al., 2025a; Yao et al., 2025; Zheng et al., 2025a), we apply token-level Importance Sampling (IS) to correct for the training–inference mismatch:
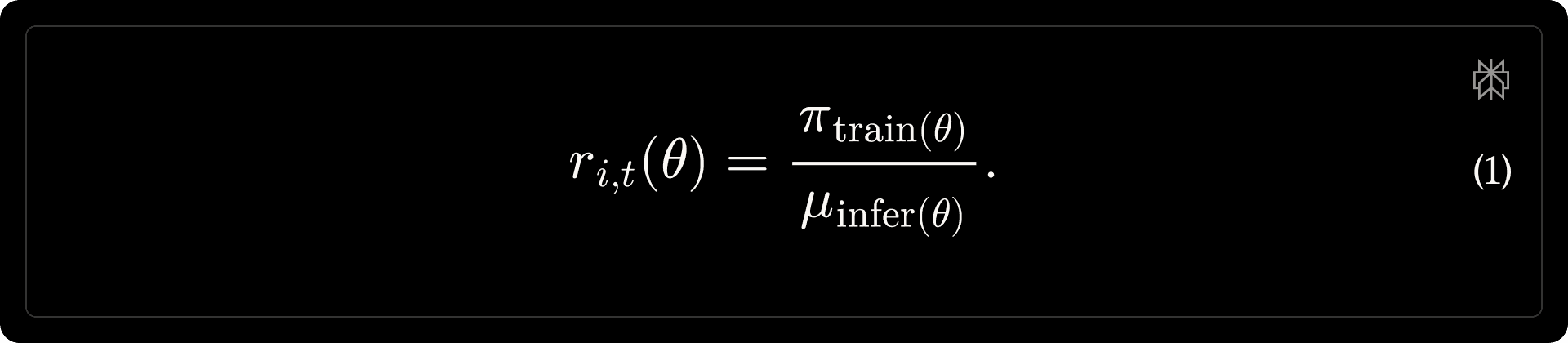
We evaluate several approaches for mitigating training-inference mismatch, including sequence-level IS (Zheng et al., 2025b), routing replay (Ma et al., 2025; Zheng et al., 2025b), and bitwise consistent training that integrates the inference engine’s kernel during training (vLLM and TorchTitan Teams, 2025). Empirically, under our on-policy setting, we find that token-level IS is sufficient to prevent training collapse while remaining simple to implement; this is consistent with the findings from Zheng et al (2025a).
RL Training Data
Our RL training data consists of two complementary components: verifiable search-agent QA targeting general search capability, and rubric-based general chat explicitly reinforcing deployment guardrails to prevent regression during the RL training stage.
Verifiable search-agent data
Dataset construction. Following the sequential expansion method (Tao et al., 2025), we construct an in-house synthetic QA dataset from internal seed queries without relying on a curated knowledge graph, keeping the pipeline lightweight and easy to refresh. Each synthetic example is generated via the following steps:
Seed selection. We retrieve documents for seed queries and select entities with multi-source fact confirmation as starting points, extracting atomic statements about them.
Multi-hop chain construction. From the seed entity’s statements, we select one that introduces a second entity (e.g., for the seed “The Mom Test”, the statement “written by Rob Fitzpatrick” introduces the author as the next entity). We repeat this linking process 2–4 times, ensuring each entity is distinct and that no single statement trivially reveals the final answer.
Name-free question synthesis. We convert the entity chain into a question by recursively replacing entity names with their connecting statements, producing a nested question that requires multi-hop reasoning.
Verification. We retain only questions with unique answers verified by multiple independent web-enabled solvers.
Example (3-hop)
Consider the seed query “The Mom Test”. We retrieve documents and identify this book as the seed entity, then extract atomic factual statements and iteratively build an entity chain: (i) The Mom Test was written by Rob Fitzpatrick, introducing Rob Fitzpatrick; (ii) Rob Fitzpatrick’s first startup went through Y Combinator (Summer 2007), introducing Y Combinator; (iii) Y Combinator was launched in March 2005. Recursively replacing each entity name with its descriptor yields the name-free question: “Which book was written by the person whose first startup went through the accelerator launched in March 2005, in its Summer 2007 cohort?” with answer “The Mom Test”.
Format-diversity augmentation. Models trained solely on raw synthetic QA tend to ignore formatting preferences and default to a fixed response structure, regardless of how the query is phrased. To improve format diversity, we augment the dataset with queries that include explicit formatting instructions (e.g., “Show a list of . . . ” or “Summarize . . . in a table”), while keeping the underlying answer unchanged.
Public verifiable QA (baseline). We construct a baseline verifiable QA dataset from five open-source datasets (Lu et al., 2025; Pham et al., 2025; Press et al., 2023; Tao et al., 2025; Wu et al., 2025), unified under our augmented prompt format with quality filtering. This mixture serves as the primary baseline in our validation experiments. For controlled comparisons, we match the scale of our in-house synthetic QA dataset to this open-source mixture.
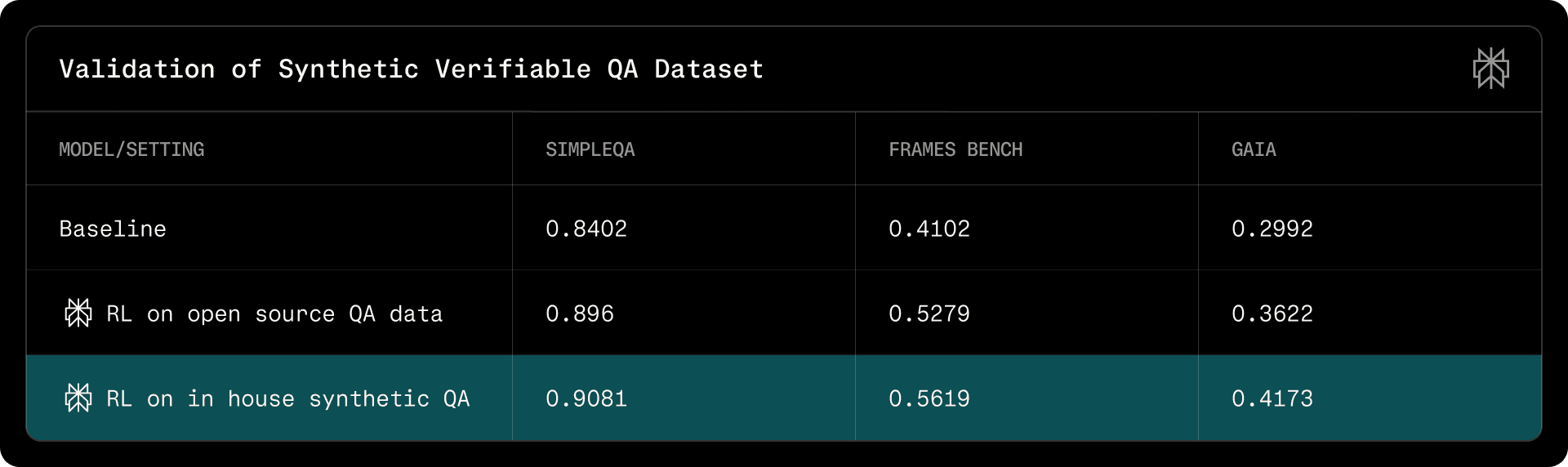
Quick validation. We validate the effectiveness of this pipeline using Qwen3-30B-A3B-Instruct-2507 to enable fast iteration; results are summarized in Table 1.
Table 1 | Validation of Synthetic Verifiable QA Dataset
Rubric-based general chat data
While verifiable QA provides a clean training signal for search-centric queries, a substantial fraction of production traffic is not uniquely verifiable (e.g., rewriting, planning, and open-ended assistance). Excluding such queries from RL would leave the policy under-optimized for real user interactions. Moreover, while the SFT stage establishes deployment-critical guardrails, RL can regress on them unless they are explicitly reinforced by the data.
We incorporate non-verifiable queries into RL training by converting deployment-critical requirements—instruction following, formatting constraints, and safety conventions—into rubrics: atomic, objectively checkable criteria that a response must satisfy. We adopt rubric-based data construction (Gunjal et al., 2025; Liu et al., 2025b), generating rubric sets per query.
Rubric generation. Given the full conversation history, we prompt an LLM to produce a reference response and a corresponding rubric set. Rubrics are derived under a fixed precedence order: requirements explicitly stated by the user take priority, followed by internal constraints, and finally necessary content requirements inferred from the reference response. Each rubric must be:
Atomic: a single, well-defined check;
Objective: verifiable without subjective judgment;
Necessary: required to answer the query, not merely a stylistic preference.
Example
Query.
She will share u man power planning. We have to arrange lodging & boarding. Plz correct swntence.
Rubrics.
The response is written in English.
The corrected wording contains the words "lodging" and "boarding".
The corrected wording uses "manpower" as a single word (for example, "manpower plan" or "manpower planning") rather than "man power".
The corrected wording does not contain the informal shorthand tokens "u" or "Plz", and it does not contain the ampersand character "&".
The response does not contain citation markers of the form
\\[type:idx\\], wheretypedenotes a data source (for example,web,chart,memory,attached_file).
Rubric calibration. To avoid overly strict or overly permissive rubric sets, we apply a pass@4 filter. For each query, we sample four independent responses and evaluate them against the full rubric set with an instruction-following judge. We discard queries for which no response satisfies the rubric set or all responses do, retaining only those that yield informative training signal.
Prompt mixture and variance balancing
A practical challenge in multi-objective RL is variance imbalance across data components (Duchi and Namkoong, 2016; Liu et al., 2026; Qi et al., 2026). Although both verifiable QA and rubric-based data yield binary rewards, they differ substantially in task difficulty: rubric satisfaction is generally easier to achieve early in training, producing larger and more frequent gradient updates that can disproportionately dominate policy optimization relative to the harder verifiable QA signal. To address this, we reweight the prompt mixture at the dataset level, sampling 90% from verifiable QA and 10% from rubric-based data to balance the optimization signal across components.
Reward design
Our reward design follows directly from the data construction described above. Despite spanning both verifiable QA and rubric tasks, all training data shares a common baseline reward structure: a rollout receives credit if it produces a correct answer for QA tasks, or satisfies all specified rubrics for general chat. Building on this shared foundation, we construct a composite reward to incorporate preference-based scoring and efficiency shaping.
A key challenge observed in early experiments was reward hacking: a simple linear combination of rewards allowed strong preference signals to compensate for factual or instructional failures. We therefore adopt gated aggregation as a core design principle, formally defined as:
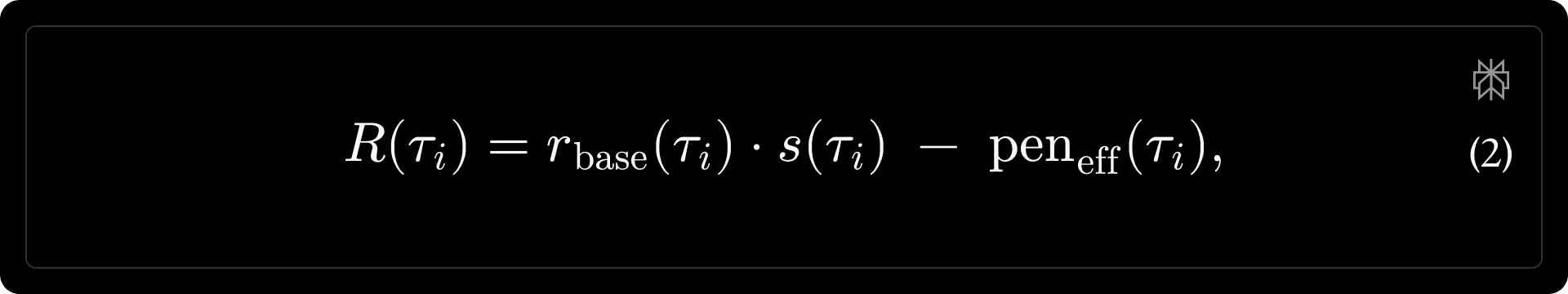
where [math]r_{\mathrm{base}}(\tau_i) \in \{0, 1\}[/math] denotes QA correctness or rubric satisfaction, [math]s(\tau_i)\in[0,1][/math] is the preference score, and [math]\operatorname{pen}_{\mathrm{eff}}(\tau_i)[/math] is an anchored efficiency penalty. This makes correctness a necessary condition for receiving preference credit, while still discouraging unnecessary tool use and verbosity. Figure 1 illustrates the full reward pipeline, the components of which we describe below:
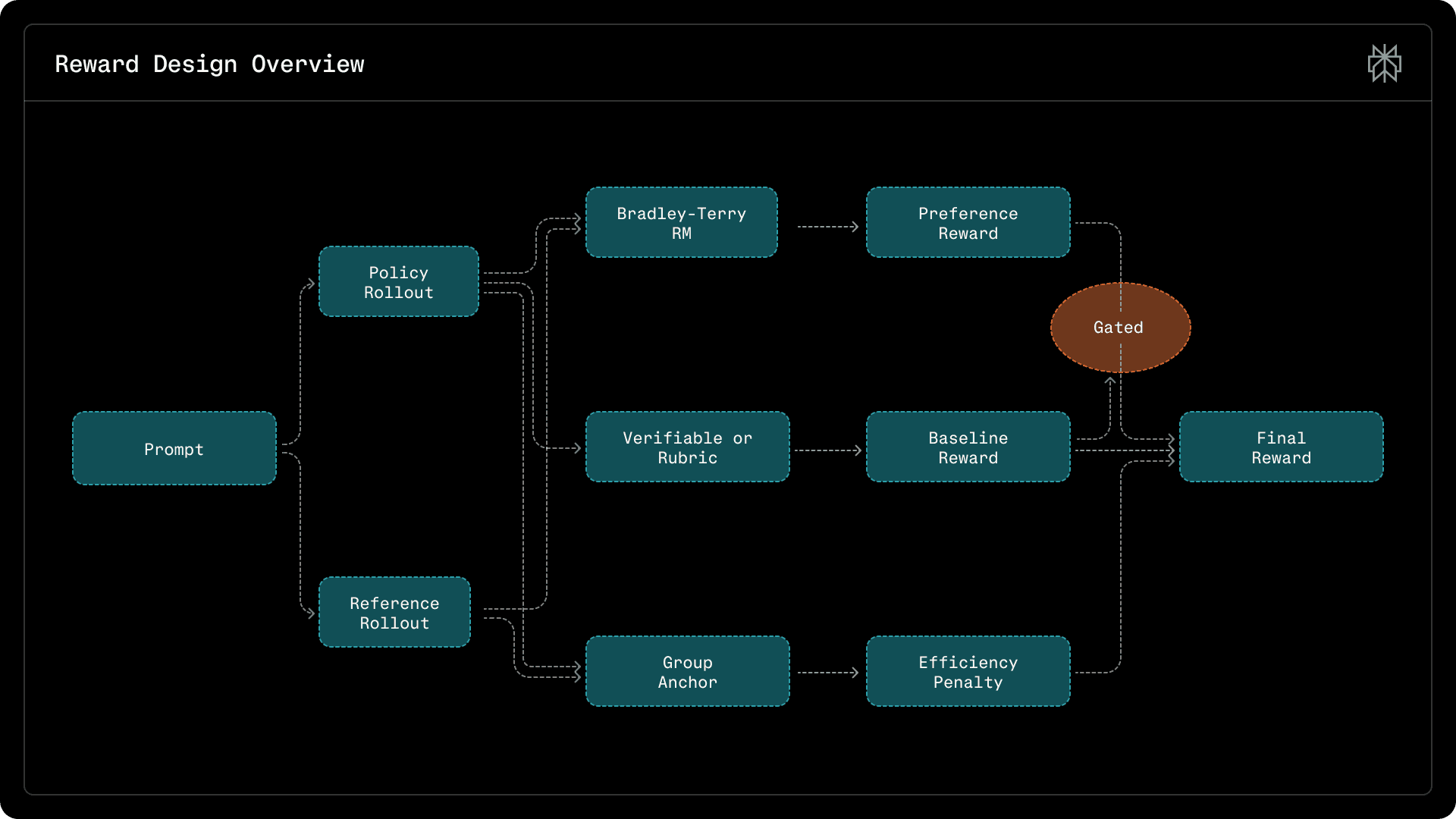
Figure 1: Reward design overview. We combine a baseline correctness signal (verifiable/rubric), a Bradley–Terry preference score, and anchored efficiency penalties. Preference is gated by baseline correctness to prevent reward hacking.
Baseline reward
We define a binary baseline signal [math]r_{\mathrm{base}}(\tau_i) \in \{0,1\}[/math] that captures task correctness or instruction compliance. For verifiable search-agent data, [math]r_{\mathrm{base}}(\tau_i)=1[/math] if the final answer matches the ground truth, and [math]0[/math] otherwise. For rubric-based general chat data, [math]r_{\mathrm{base}}(\tau_i)=1[/math] if all rubrics are satisfied, and [math]0[/math] otherwise. This baseline serves as the hard gate in the conditional aggregation rule Eq. 2.
Preference modeling
We aim to align the policy model with users' latent preferences over response quality—informativeness, clarity, and professional tone—which are difficult to capture via LLM-judge prompts. We therefore train a learned preference reward model to score these attributes directly.
We formulate preference learning under the Bradley–Terry framework. Given a context [math]x[/math] and two candidate responses [math]y_a, y_b[/math], the model produces scalar scores [math]s_{\theta}(x, y) \in \mathbb{R}[/math] and minimizes,
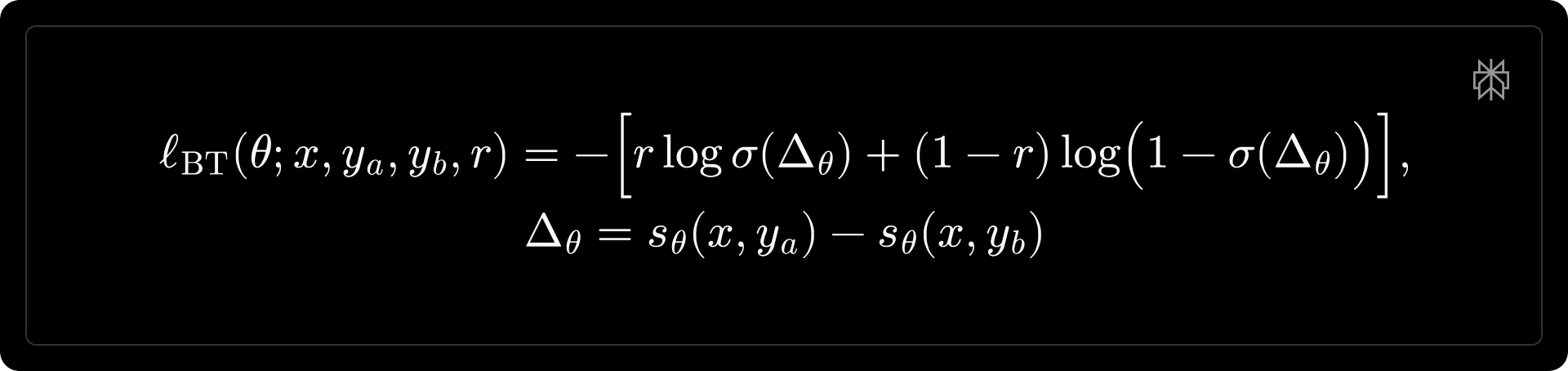
where [math]r \in \{0, 1\}[/math] indicates whether [math]y_a[/math] is preferred. To eliminate positional bias, each training pair is augmented with both orderings and optimized symmetrically,
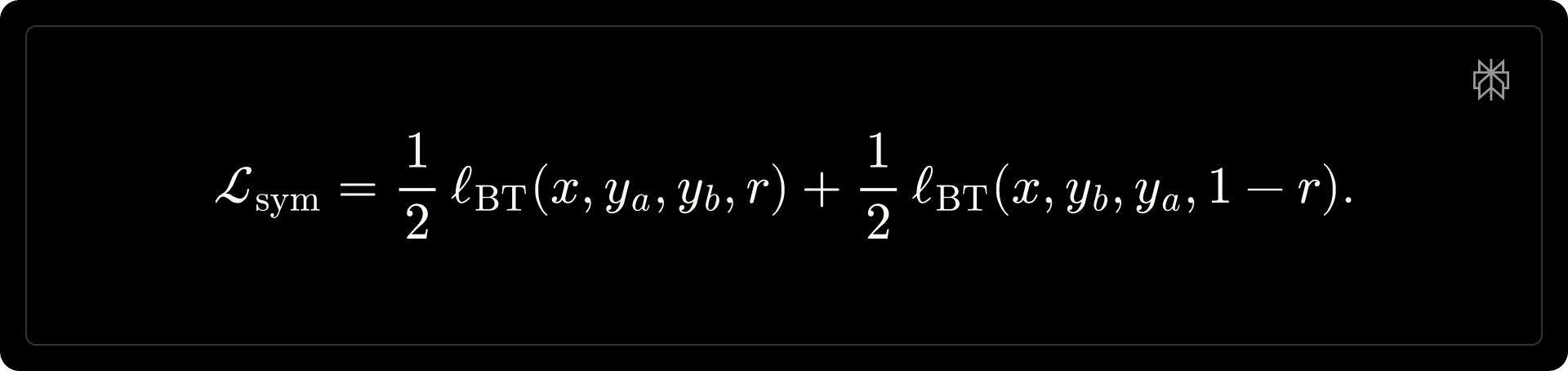
At inference time, we obtain a position-agnostic preference score by averaging both permutations:
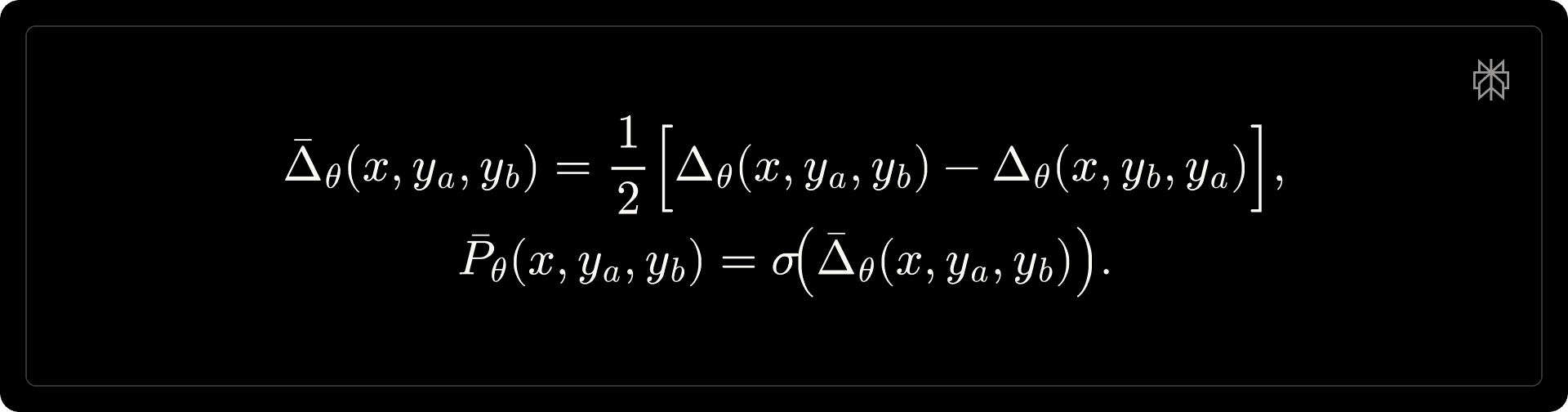
The rollout preference score is then defined as [math]s(\tau_i) \triangleq \bar{P}_{\theta}(x, y_a, y_b) \in [0,1][/math], i.e., the probability that the policy rollout [math]y_i[/math] is preferred over the reference model rollout for the same prompt.
Training data for preference modeling is drawn from curated open-source datasets, user side-by-side feedback, and internal annotations. To address label noise, we apply a lightweight filtering and calibration pipeline inspired by Datbench (DatologyAI, 2026), retaining only examples with consistent cross-model agreement. The reward model shares the same backbone as the policy model, with the language modeling head replaced by a value head. While smaller reward models achieve comparable held-out accuracy, we find empirically that they fail to capture fine-grained preferences and can reinforce undesirable policy behaviors.
Efficiency penalty
In the absence of explicit efficiency shaping, the policy tends to overuse tools even on simple prompts. Unconditional penalties (e.g., those scaling linearly with tool-call count or output length) are a natural baseline, but we find they suppress necessary exploration and degrade learning. We therefore adopt group-relative, anchored penalties that regularize tool usage and response length relative to effective solutions within each GRPO group. For a group 𝑔, we define the winner set as:
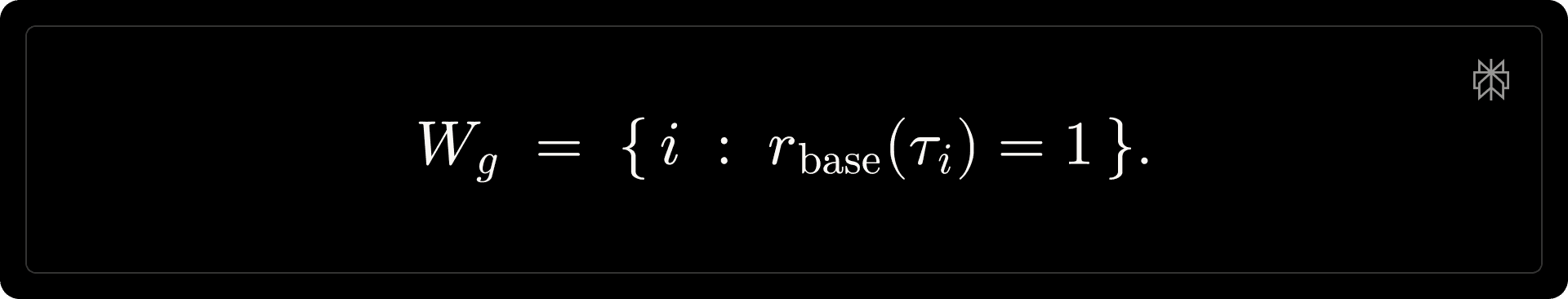
Anchored tool-call penalty. For each rollout [math]\tau_i[/math], let [math]c_i[/math] denote the number of tool calls and [math]e_i[/math] the number of tool-execution failures. We define the effective tool-call count [math]\tilde{c}_i = c_i - e_i[/math] and uniformly sample a group baseline:
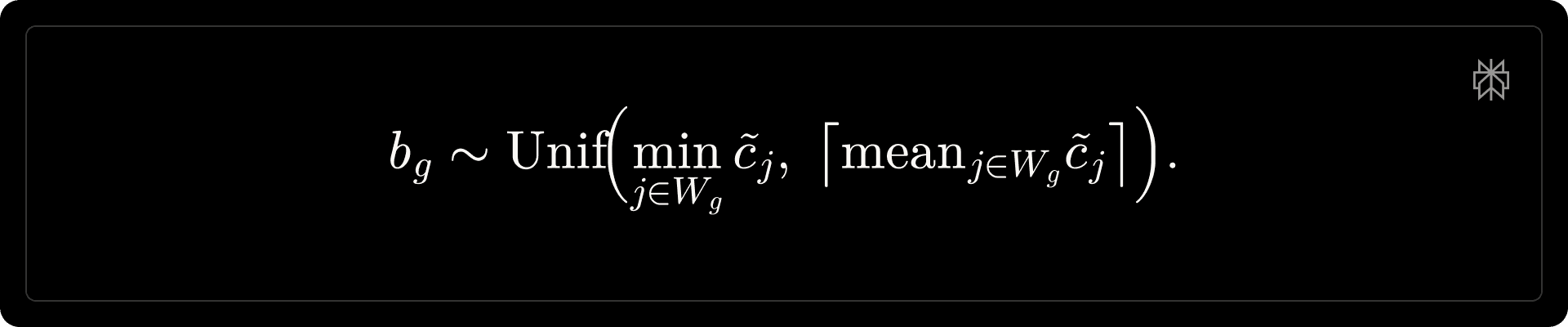
We compute the excess [math]\Delta_i = \max\!\left(0,\; \tilde{c}_i - b_g\right)[/math], and define a smooth penalty scalar [math]p_i = 1 - \exp\!\left(-\Delta_i\right)[/math]. The tool penalty is then:
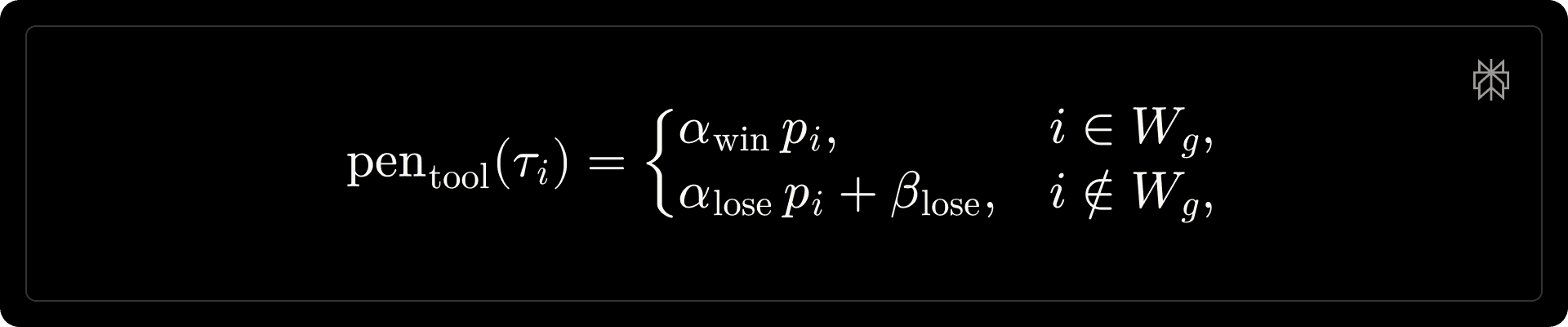
Anchored length penalty. Let [math]L_i[/math] and [math]L_i^{\mathrm{ref}}[/math] denote the token lengths of the candidate and reference model generations, respectively. We define the shaping set [math]\widehat{W}_g[/math] as rollouts that are both correct and preferred:
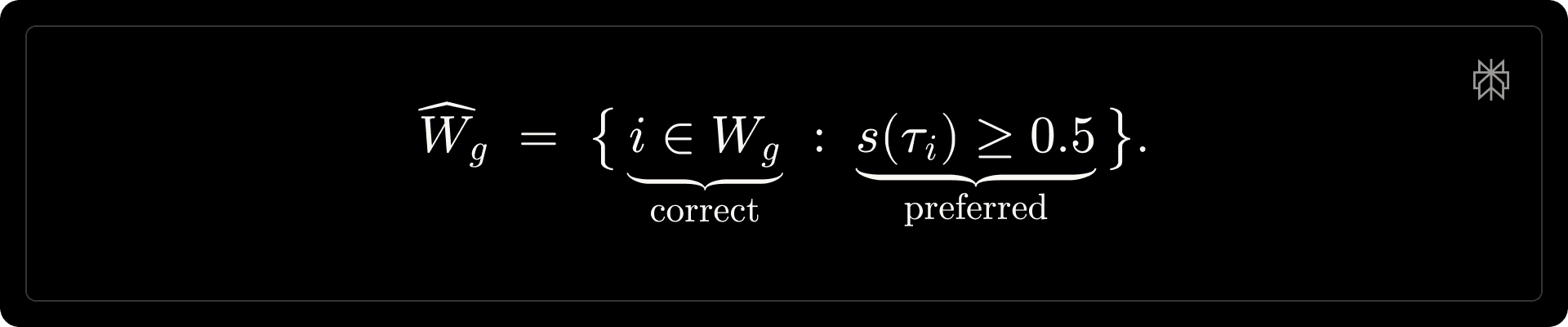
We then compute group-specific length baselines:
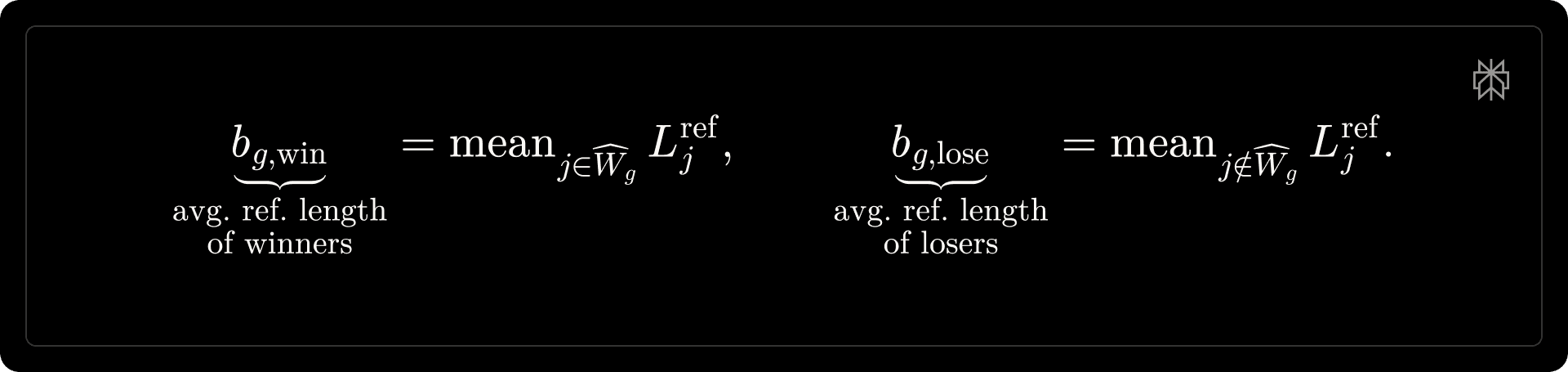
The length penalty is defined as:
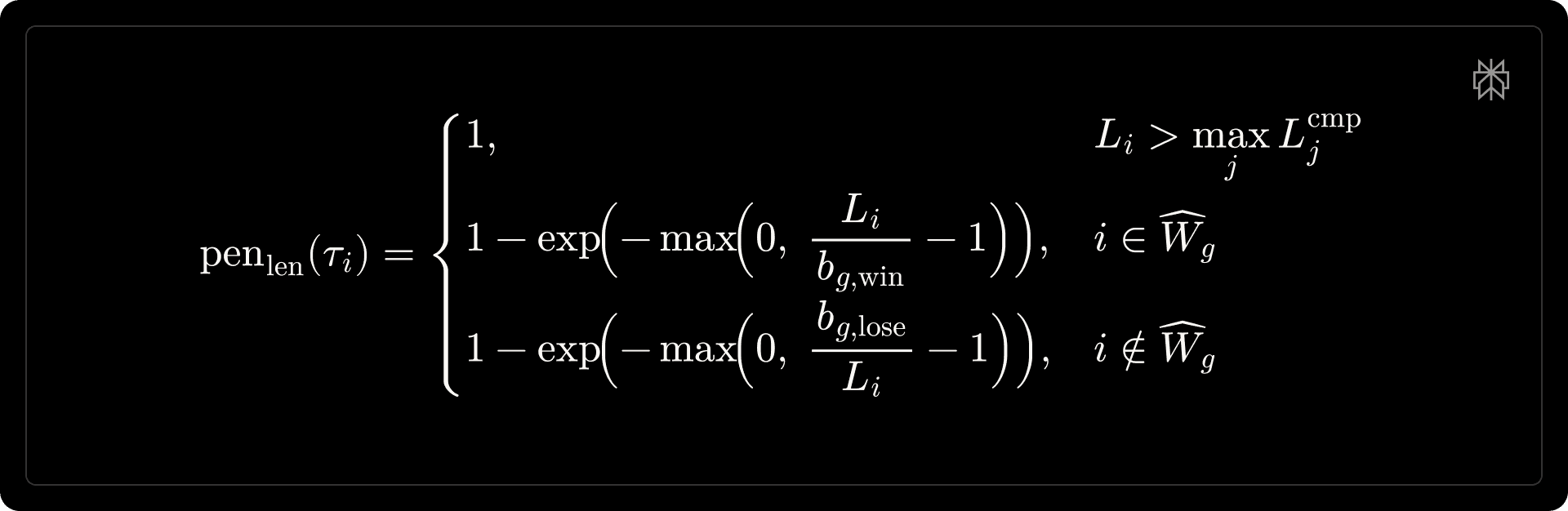
where the first line is a hard cap; the second penalizes verbose winners; and the third penalizes terse losers.
Combined efficiency penalty. The combined efficiency penalty is a weighted sum of both components:

Main results
We evaluate our post-training pipeline along two axes: (i) training dynamics, to assess optimization stability and whether the reward signals behave as expected, and (ii) offline benchmarks, to measure downstream quality, safety, and efficiency under controlled evaluation settings.
Default training settings. The policy model interacts with a web search tool (search_web); each tool call retrieves up to 10 results, with queries capped at 250 characters and up to 5 queries per rollout.
Training dynamics
We examine optimization dynamics, focusing on reward progression and efficiency behavior. We use Qwen3.5-397B-A11B for simplicity of illustration.
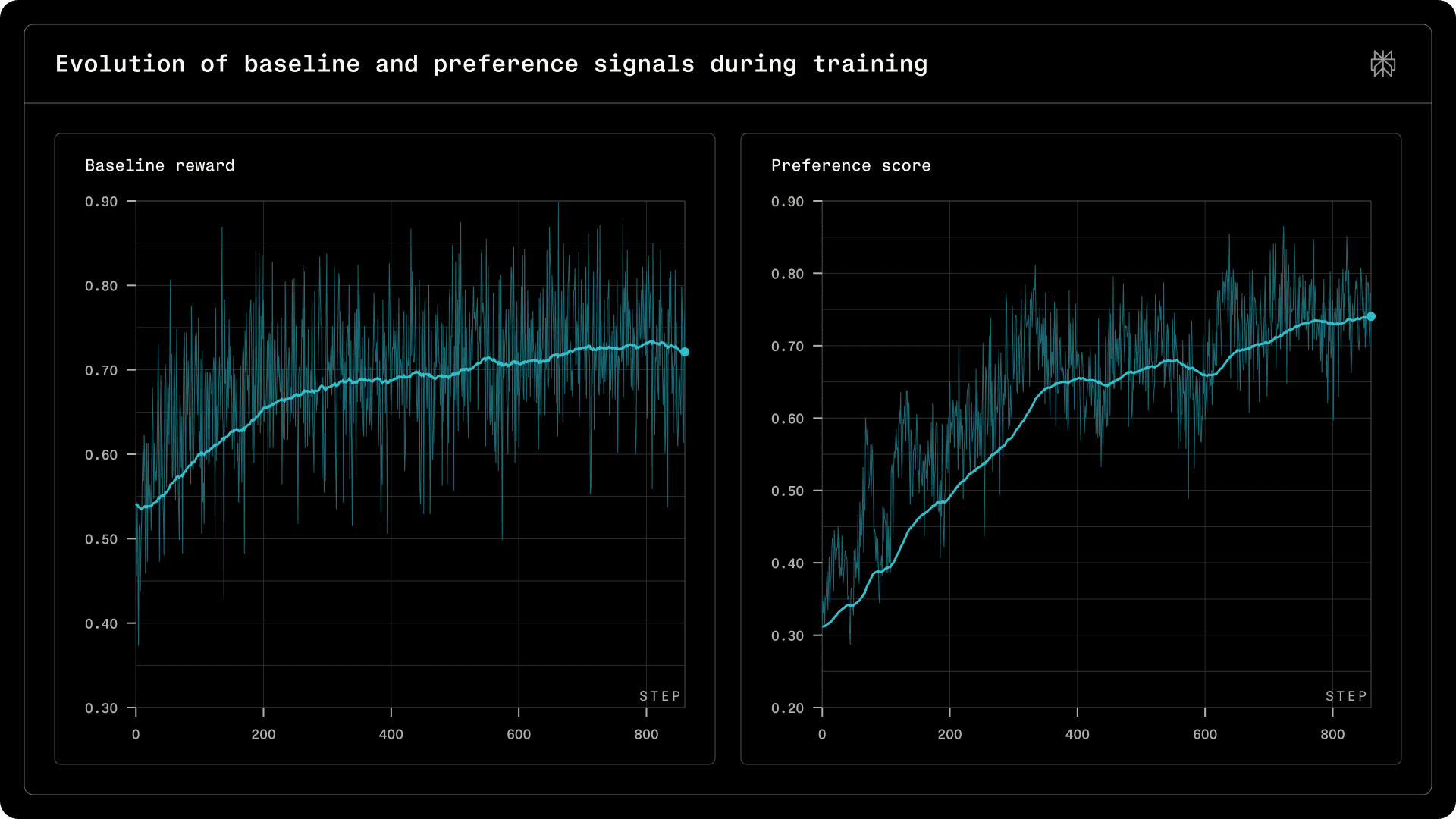
Figure 2 | Evolution of baseline and preference signals during training.
Figure 2 shows steady improvement in the baseline reward (verifiable QA and rubric satisfaction) alongside increasing preference scores, indicating consistent gains in correctness, compliance, and response quality.
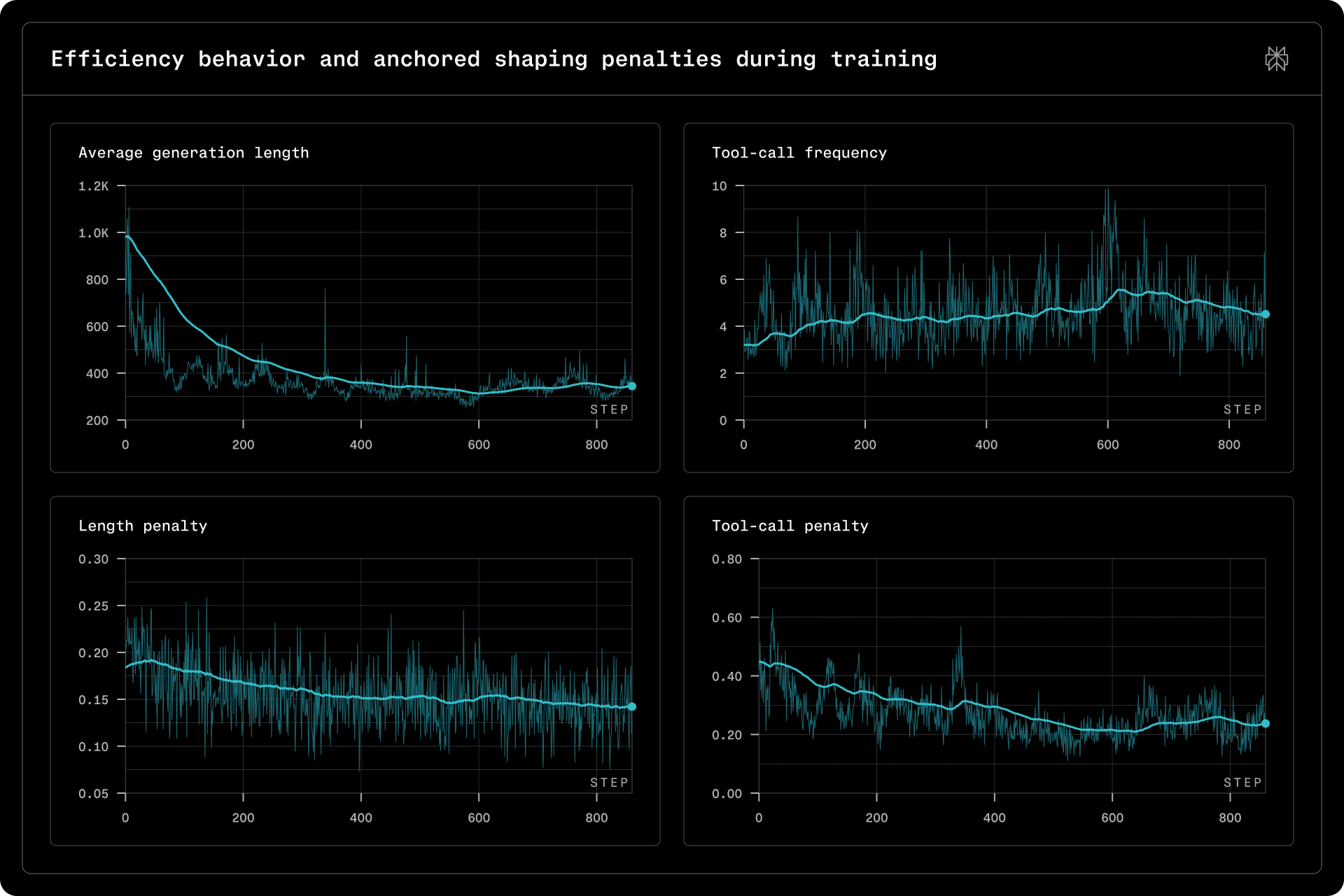
Figure 3 | Efficiency behavior and anchored shaping penalties during training.
Figure 3 demonstrates that both tool-call frequency and generation length remain well-controlled throughout training. Notably, both the tool-call and length penalties decrease monotonically over the course of training, reflecting the model’s progressive adaptation toward more concise generation and more selective tool invocation.
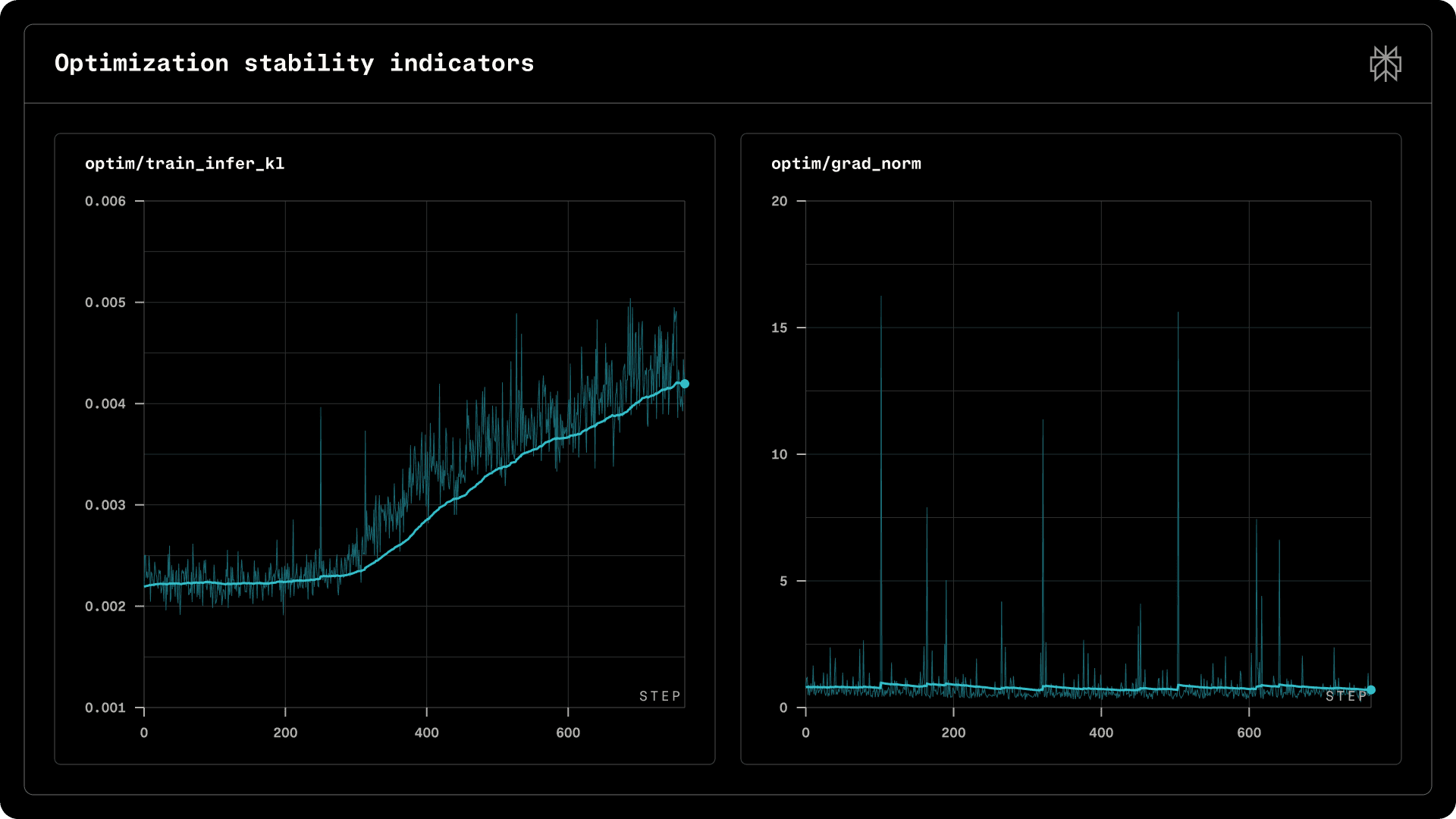
Figure 4 | Optimization stability indicators.
Figure 4 shows that gradient norms remain stable aside from transient spikes, while the training-inference KL divergence exhibits a mild upward trend, staying within the 1e-3 scale. This drift pattern is consistent with observations in other RL training frameworks; as training remains stable throughout, we retain a simple IS regularization in Eq. 1 without additional intervention.
Offline evaluations
We report results on a suite of benchmarks spanning search accuracy, factual reliability, instruction following, and safety, comprising both public benchmarks and internal Perplexity (PPLX) metrics. Public benchmarks include SimpleQA, FRAMES, and Facts Open.
pplx-sbs-search: Side-by-side preference evaluation using an internal reward model. Candidates are compared against a strong baseline.
pplx-abstention: Ability to refuse appropriately when no reliable evidence is available.
pplx-language-mismatch: Language consistency under long-tail and multi-turn settings.
pplx-broken-tool-calls (↓): Tool-call schema compliance and constraint following, for example,
tool_choice=none.
Default evaluation settings. For public benchmarks, we allow only the web-search tool, with a budget of up to 5 tool calls per example and up to 10 results per call, generating up to 8192 output tokens at temperature 0.6.
Table 2 | Offline evaluation results. Numbers in parentheses indicate average tool usage. We note Qwen3.5-397B-A17B as Qwen3.5-Large, and Qwen3.5-122B-A10B as Qwen3.5-Medium.
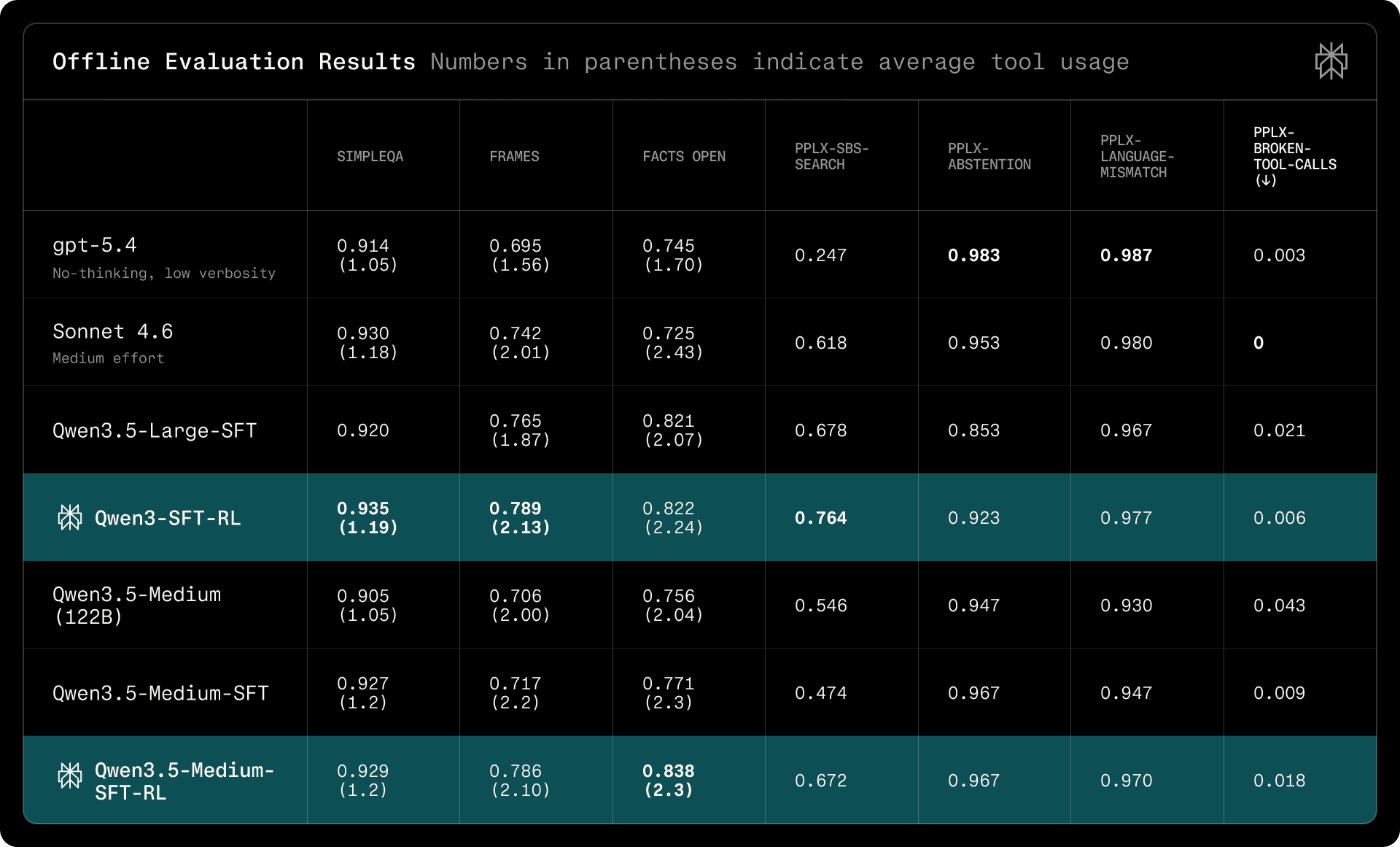
Table 2 shows that Qwen3.5-Large-SFT-RL achieves strong search accuracy across public benchmarks, matching or exceeding gpt-5.4 on FRAMES and Facts Open while using comparable tool budgets. Relative to the base model, our approach yields substantial gains on internal metrics, particularly on preference (pplx-sbs-search: 0.602 → 0.742), language consistency, and abstention, demonstrating that the two-stage pipeline effectively improves deployment-critical behaviors without compromising search capability.
Tool Use Efficiency Evaluations
To measure this, we design a budget-forced evaluation protocol. Each model is given access to a web search tool (search_web) and a system prompt that specifies a hard cap on the number of tool calls allowed (the "budget"). We sweep this budget from 0 (no tool use, pure parametric knowledge) to 10 (generous multi-step retrieval), recording accuracy at each level. This produces a tool-efficiency curve: the model's score as a function of the retrieval budget it is allowed. We evaluate on two factual QA benchmarks, FRAMES and Facts Open.
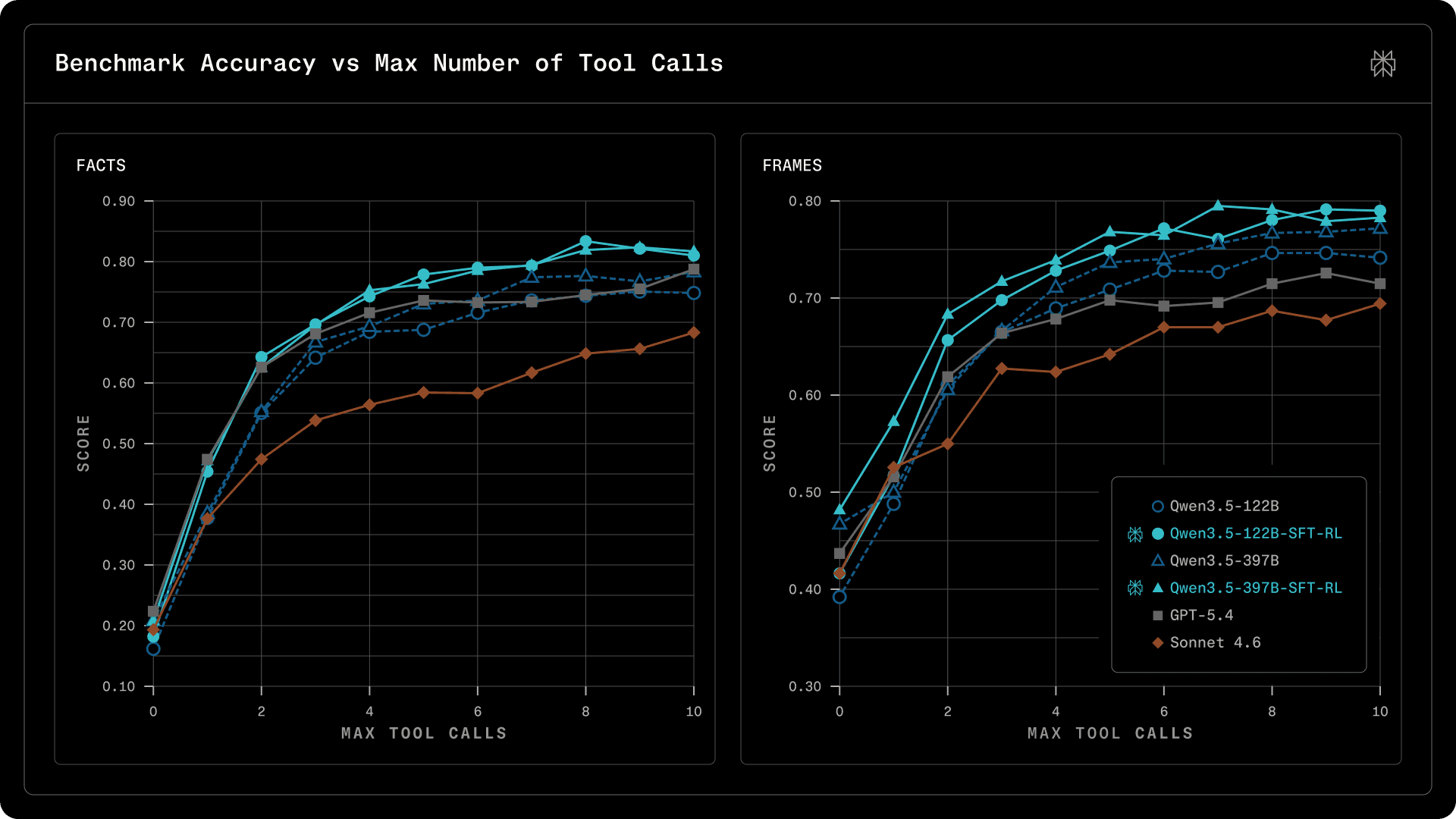
Figure 5. Benchmark Accuracy vs Max Number of Tool Calls.
Several patterns stand out from these two benchmarks:
Our post-trained Qwen3.5-397B-SFT-RL achieves the best search accuracy on both benchmarks. Even with a single tool call, it scores 57.3% on FRAMES, 5.7 points above GPT-5.4 and 4.7 points above Sonnet 4.6.
The advantage is most pronounced at moderate budgets (b=2-7), which is the practical operating range for production deployments.
Our post-training recipe (SFT + RL) substantially improves tool-use efficiency over the base checkpoint; see solid lines (post-trained) vs. dashed lines (starting checkpoint) in Figure 5.
For all models, we observe diminishing returns around budget=7, consistent across two benchmarks and all models, suggesting it is a property of the factuality-seeking tasks rather than the models.
The results above show that Qwen3.5-397B-SFT-RL achieves higher accuracy with fewer tool calls. But how does this translate to actual cost? We convert token-level measurements to dollar costs using published API pricing (Alibaba DashScope, OpenAI, Anthropic) to make the comparison concrete.
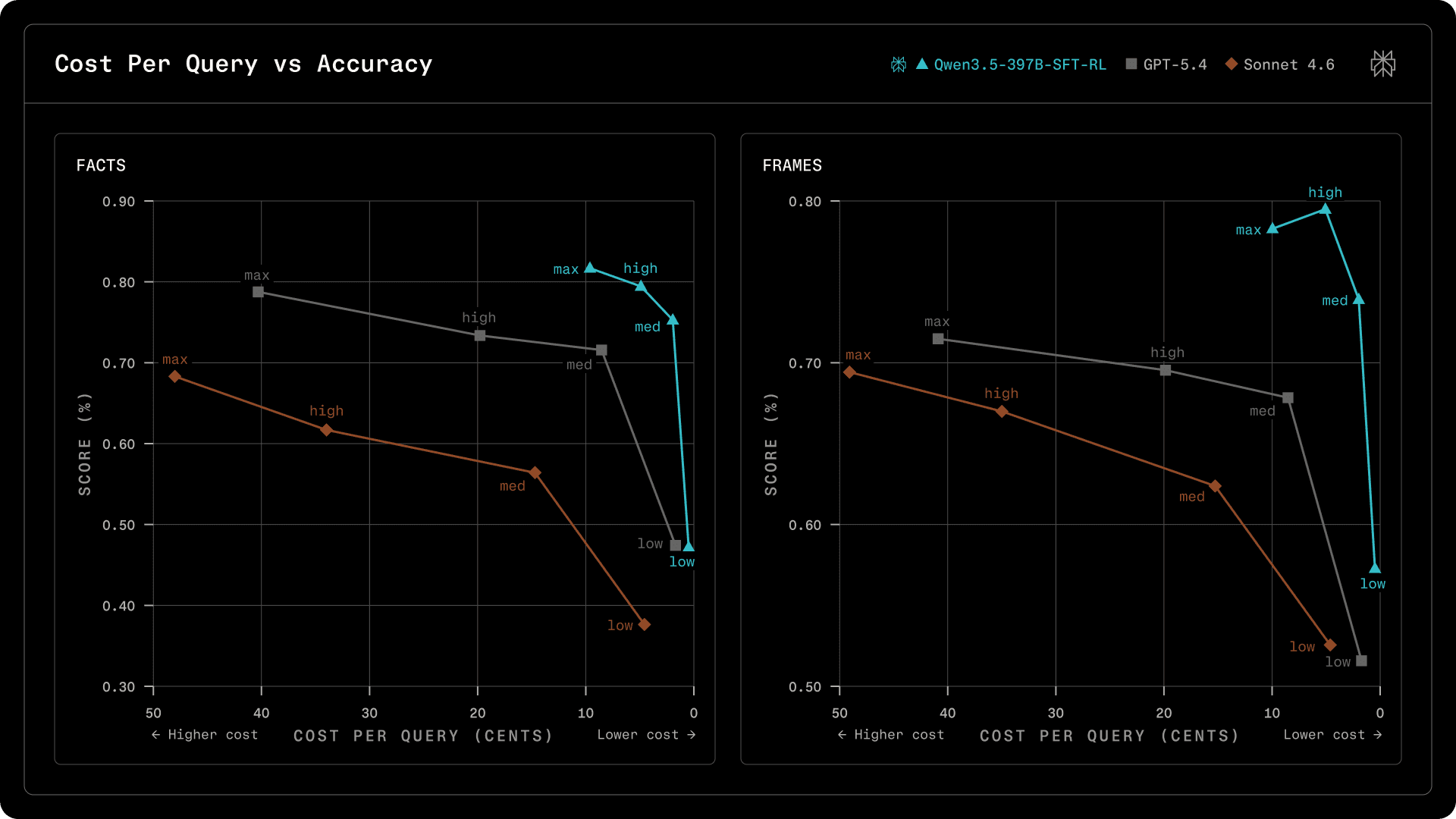
Figure 6. Cost Per Query vs Accuracy.
At the medium profile (b=4), Qwen3.5-397B-SFT-RL scores 73.9% on FRAMES at 2.0 cents per query, while GPT-5.4 scores 67.8% at 8.5 cents and Sonnet 4.6 scores 62.4% at 15.3 cents. That is +6 points accuracy at 4x lower cost compared to GPT-5.4, and +11.5 points at 7.5x lower cost compared to Sonnet 4.6.
These estimates use list API pricing without caching. With in-house inference optimizations such as KV cache reuse, prefix caching, and quantized MoE serving (397B uses only 17B active parameters), the effective cost can be reduced well below list API pricing.
Conclusion
Disentangling deployment compliance from search optimization via a two-stage SFT and RL pipeline yields a model that is both capable and reliable under production constraints. The combination of verifiable QA and rubric-based training data, together with gated reward aggregation and anchored efficiency shaping, enables stable multi-objective optimization without sacrificing search accuracy or guardrail compliance.
Several directions merit further investigation. As observed in Figure 4, the training–inference KL divergence exhibits a persistent upward drift at extended training steps. While token-level IS correction proves sufficient under our current setting, whether this remains true at larger scale is unclear; a more principled theoretical treatment of this mismatch — encompassing infrastructure-level discrepancies and architecture-specific factors such as MoE routing — alongside quantitative empirical comparisons of mitigation strategies, remains an important open question. For multi-objective RL specifically, promising avenues include sequential training (Zeng et al., 2026) with on-policy distillation to optimize objectives in stages while mitigating catastrophic forgetting; and model merging (Fu et al., 2025; Yang et al., 2026) to decouple task-specific optimization from capability aggregation. Finally, scaling to realistic multi-tool workflows with long-horizon trajectories remains an important open challenge, likely requiring better credit assignment, support for partial rollouts, and evaluations.
References
DatologyAI. Datbench: Discriminative, faithful, and efficient vision-language model evaluations. https://www.datologyai.com/blog/datbench-discriminative-faithful-and-efficient-vision-language-model-evaluations, Jan. 2026. Published Jan 6, 2026. Accessed: 2026-03-04.
J. Duchi and H. Namkoong. Variance-based regularization with convex objectives. arXiv preprint arXiv:1610.02581, 2016.
Z. Fu, X. Wu, Y. Wang, W. Wang, S. Ye, H. Yin, Y. Chang, Y. Zheng, and X. Zhao. Training-free llm merging for multi-task learning. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 33111–33124, 2025.
A. Gunjal, A. Wang, E. Lau, V. Nath, Y. He, B. Liu, and S. Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains. arXiv preprint arXiv:2507.17746, 2025.
J. Liu, Y. Li, Y. Fu, J. Wang, Q. Liu, and Y. Shen. When speed kills stability: Demystifying rl collapse from the training-inference mismatch. Notion Blog, 2025a.
S.-Y. Liu, X. Dong, X. Lu, S. Diao, P. Belcak, M. Liu, M.-H. Chen, H. Yin, Y.-C. F. Wang, K.-T. Cheng, et al. Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization. arXiv preprint arXiv:2601.05242, 2026.
T. Liu, R. Xu, T. Yu, I. Hong, C. Yang, T. Zhao, and H. Wang. Openrubrics: Towards scalable synthetic rubric generation for reward modeling and llm alignment. arXiv preprint arXiv:2510.07743, 2025b.
R. Lu, Z. Hou, Z. Wang, H. Zhang, X. Liu, Y. Li, S. Feng, J. Tang, and Y. Dong. Deepdive: Advancing deep search agents with knowledge graphs and multi-turn rl. arXiv preprint arXiv:2509.10446, 2025.
W. Ma, H. Zhang, L. Zhao, Y. Song, Y. Wang, Z. Sui, and F. Luo. Stabilizing moe reinforcement learning by aligning training and inference routers. arXiv preprint arXiv:2510.11370, 2025.
T. Pham, N. Nguyen, P. Zunjare, W. Chen, Y.-M. Tseng, and T. Vu. Sealqa: Raising the bar for reasoning in search-augmented language models. arXiv preprint arXiv:2506.01062, 2025.
O. Press, M. Zhang, S. Min, L. Schmidt, N. A. Smith, and M. Lewis. Measuring and narrowing the compositionality gap in language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, 2023.
P. Qi, X. Zhou, Z. Liu, T. Pang, C. Du, M. Lin, and W. S. Lee. Rethinking the trust region in llm reinforcement learning. arXiv preprint arXiv:2602.04879, 2026.
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
Z. Tao, J. Wu, W. Yin, J. Zhang, B. Li, H. Shen, K. Li, L. Zhang, X. Wang, Y. Jiang, et al. Webshaper: Agentically data synthesizing via information-seeking formalization. arXiv preprint arXiv:2507.15061, 2025.
vLLM and TorchTitan Teams. No more train-inference mismatch: Bitwise consistent on-policy reinforcement learning with vLLM and TorchTitan. https://blog.vllm.ai /2025/11/10/bitwise-consistent-train-inference.html, nov 2025. vLLM Blog.
J. Wu, W. Yin, Y. Jiang, Z. Wang, Z. Xi, R. Fang, D. Zhou, P. Xie, and F. Huang. Webwalker: Benchmarking llms in web traversal, 2025. URL https://arxiv.org/abs/ 2501.07572.
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025.
E. Yang, L. Shen, G. Guo, X. Wang, X. Cao, J. Zhang, and D. Tao. Model merging in llms, mllms, and beyond: Methods, theories, applications, and opportunities. ACM Computing Surveys, 58(8):1–41, 2026.
F. Yao, L. Liu, D. Zhang, C. Dong, J. Shang, and J. Gao. Your efficient rl framework secretly brings you off-policy rl training, Aug. 2025. URL https://fengyao.notion.s ite/off-policy-rl.
A. Zeng, X. Lv, Z. Hou, Z. Du, Q. Zheng, B. Chen, D. Yin, C. Ge, C. Xie, C. Wang, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763, 2026.
C. Zheng, K. Dang, B. Yu, M. Li, H. Jiang, J. Lin, Y. Liu, H. Lin, C. Wu, F. Hu, et al. Stabilizing reinforcement learning with llms: Formulation and practices. arXiv preprint arXiv:2512.01374, 2025a.
C. Zheng, S. Liu, M. Li, X.-H. Chen, B. Yu, C. Gao, K. Dang, Y. Liu, R. Men, A. Yang, et al. Group sequence policy optimization. arXiv preprint arXiv:2507.18071, 2025b.