research
Evaluating Deep Research Performance in the Wild with the DRACO Benchmark
DRACO: a Cross-Domain Benchmark for Deep Research Accuracy, Completeness, and Objectivity

Today, we are releasing the Deep Research Accuracy, Completeness, and Objectivity (DRACO) Benchmark, an open benchmark for evaluating deep research agents grounded in how users actually use AI for complex research tasks. By open sourcing DRACO, we aim to help the broader AI community build research tools that better serve real user needs.
DRACO highlights the gap between solving synthetic tasks and serving authentic research needs. The evaluation harness is model agnostic: as stronger agentic LLMs emerge, we will rerun evaluations and publish updated results. And as we ship improvements to Deep Research on Perplexity.ai, users will see those gains reflected in both product performance and benchmark scores.
State-of-the-art Deep Research
Perplexity Deep Research achieves state-of-the-art performance on leading external benchmarks, including Google DeepMind's DeepSearchQA and Scale AI's ResearchRubrics.

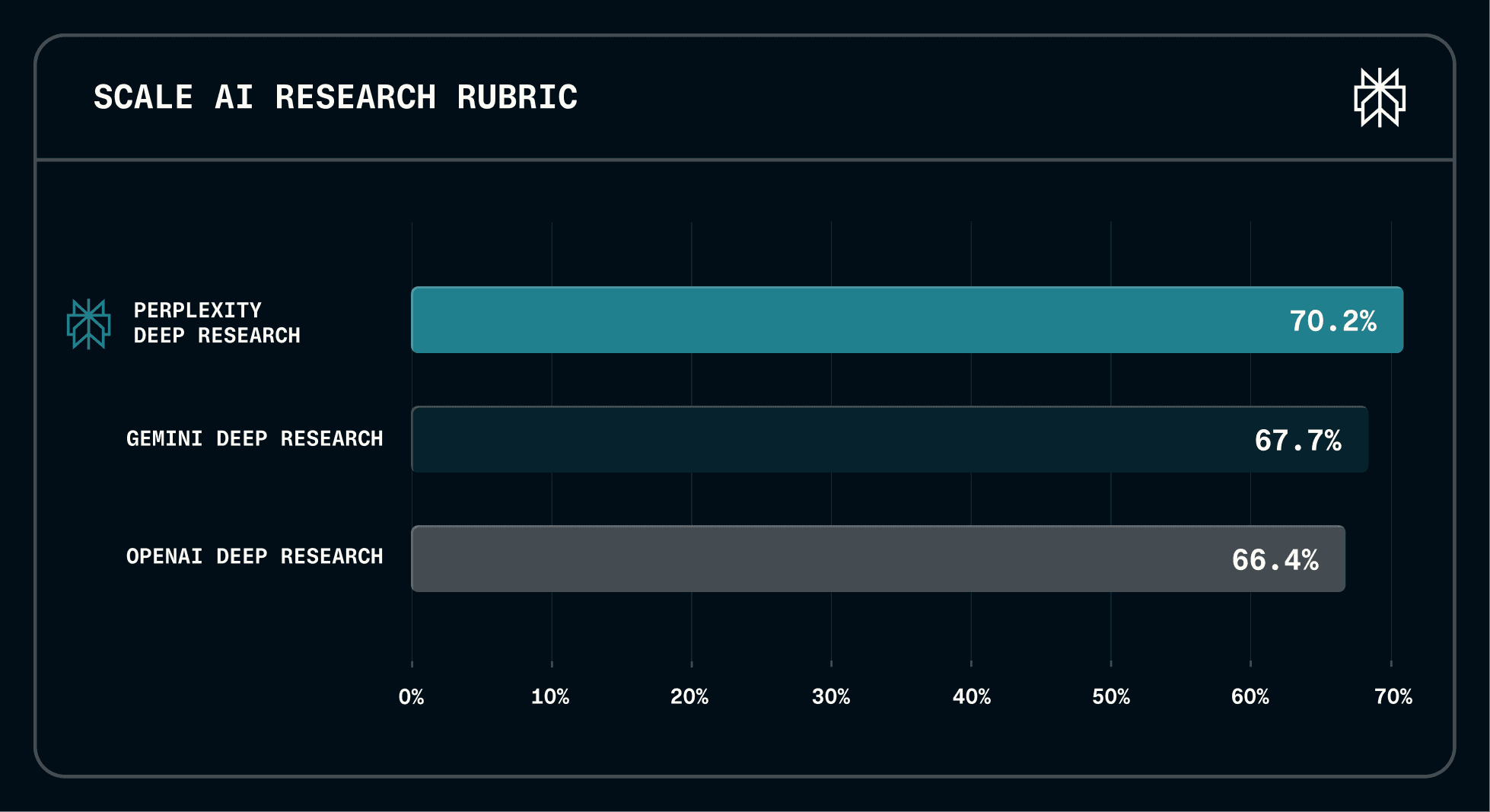
These results stem from combining the best available models with Perplexity's purpose-built agentic capabilities: proprietary search tools, browser infrastructure, and code execution. Together, these form a system optimized end-to-end for retrieving, synthesizing, and reasoning over real-world information.
In the process of building this product, we realized that external benchmarks, while useful for comparing models, often don't capture the multifaceted queries and synthesis demands that real users ask every day. Today, we are open-sourcing DRACO Benchmark, a benchmark grounded in how people actually use deep research, motivated by millions of production tasks across ten domains.
Why production-grounded evaluation matters
Existing benchmarks often test narrow skills in isolation: retrieving a single fact, answering a trivia question, or solving a well-defined problem. But real research queries demand synthesis across sources, nuanced analysis, and actionable guidance, all while maintaining factual accuracy and proper citation.
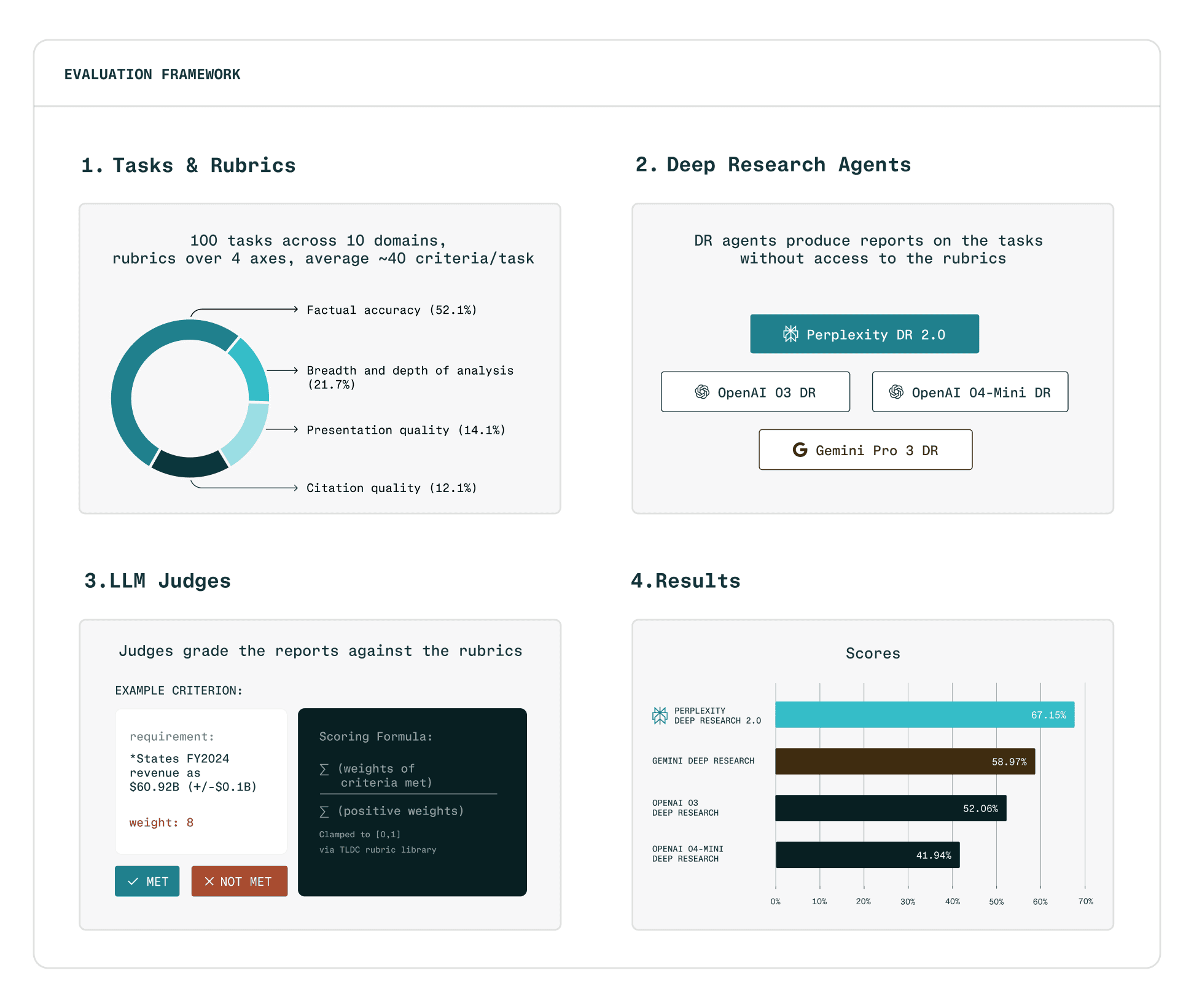
DRACO Benchmark comprises 100 carefully curated tasks spanning Academic, Finance, Law, Medicine, Technology, General Knowledge, UX Design, Personalized Assistant, Shopping/Product Comparison and Needle in a Haystack, each paired with expert crafted rubrics averaging ~40 evaluation criteria.
These tasks originate from actual user requests on Perplexity Deep Research, sampled from millions of production requests and then systematically reformulated, augmented, and filtered through a five stage pipeline: we remove personally identifiable information, add context and scope, filter for objectivity and difficulty, and conduct final review by domain experts. The result is a benchmark that reflects authentic user needs rather than synthetic exercises or expert curated tasks.
How DRACO Benchmark works
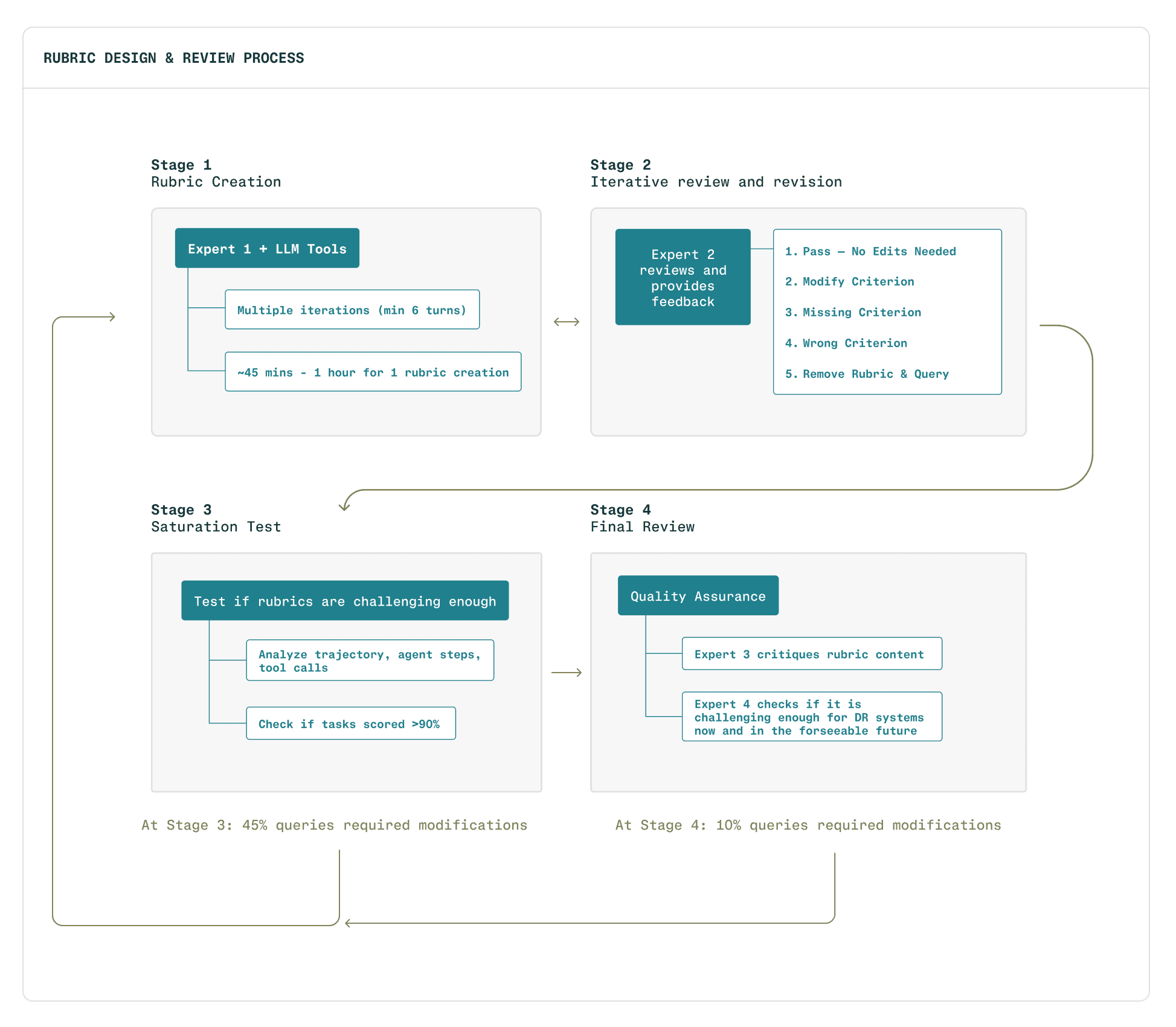
Each task in the benchmark went through a rigorous rubric development process. Perplexity worked with a data generation partner, The LLM Data Company, to develop and pressure-test evaluation rubrics for the set. Subject matter experts drafted initial rubrics with the aid of LLM tooling, then iterated through peer review and calibration. Ill-specified and overly lenient rubrics were returned for revision, with roughly 45% of rubrics refined at least once through this process. The result is evaluation criteria that genuinely distinguish system capabilities.
Rubrics assess four dimensions: factual accuracy (roughly half of all criteria), breadth and depth of analysis, presentation quality, and citation of primary sources. Each criterion receives a weight reflecting its importance and some criteria are negative, penalizing errors like hallucinations or unsupported claims.
Responses are graded using an LLM-as-judge protocol, where each criterion receives a binary verdict. This approach is well-suited for factual accuracy evaluation because rubrics ground the judge in real-world data derived from search results, transforming subjective assessment into verifiable fact-checking. We validated reliability across three judge models and found that while absolute scores vary, relative system rankings remain consistent.
Toolset and evaluation environment
The benchmark is designed to evaluate agents with access to a full research toolset, including a code execution sandbox and browser capabilities.
What we found
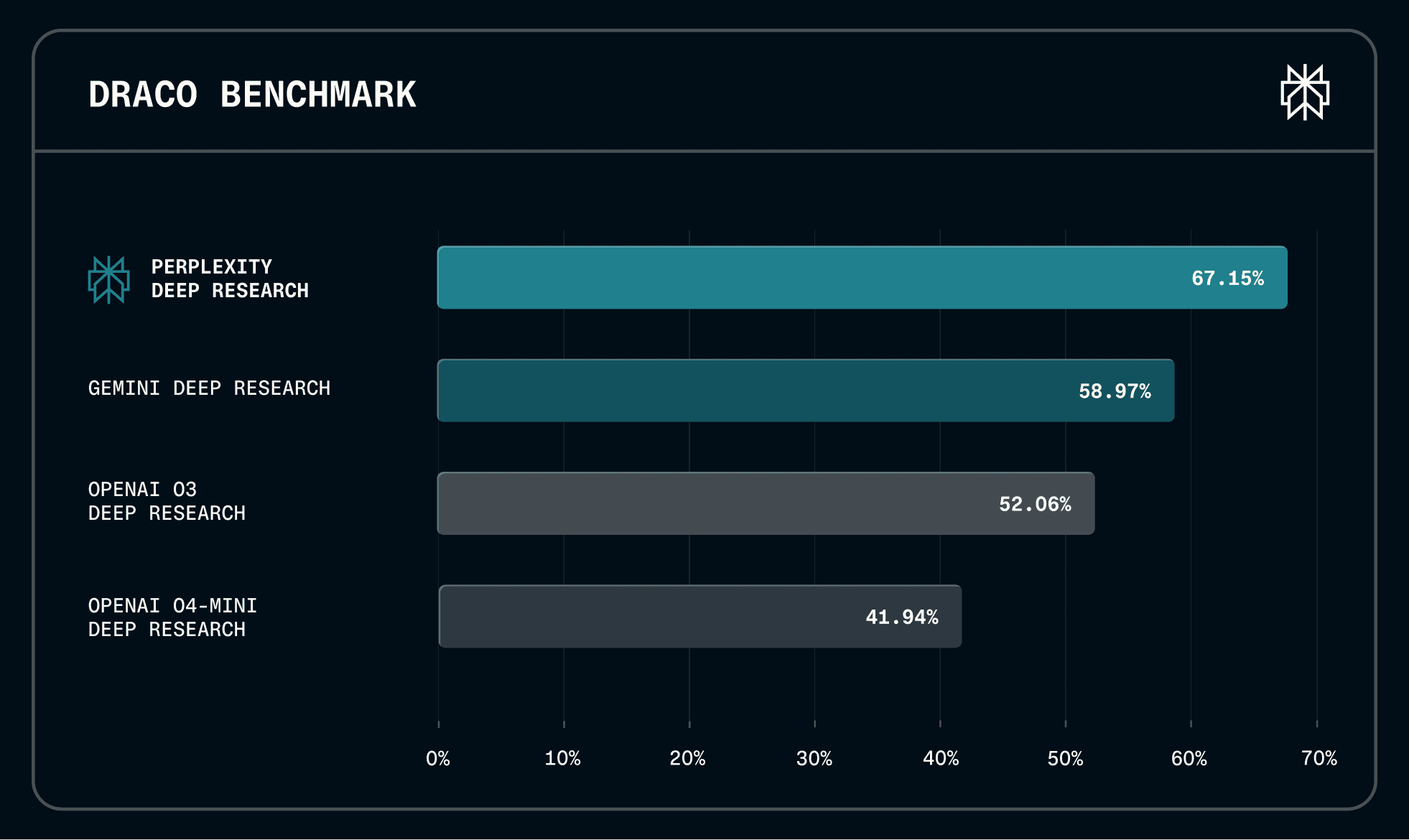
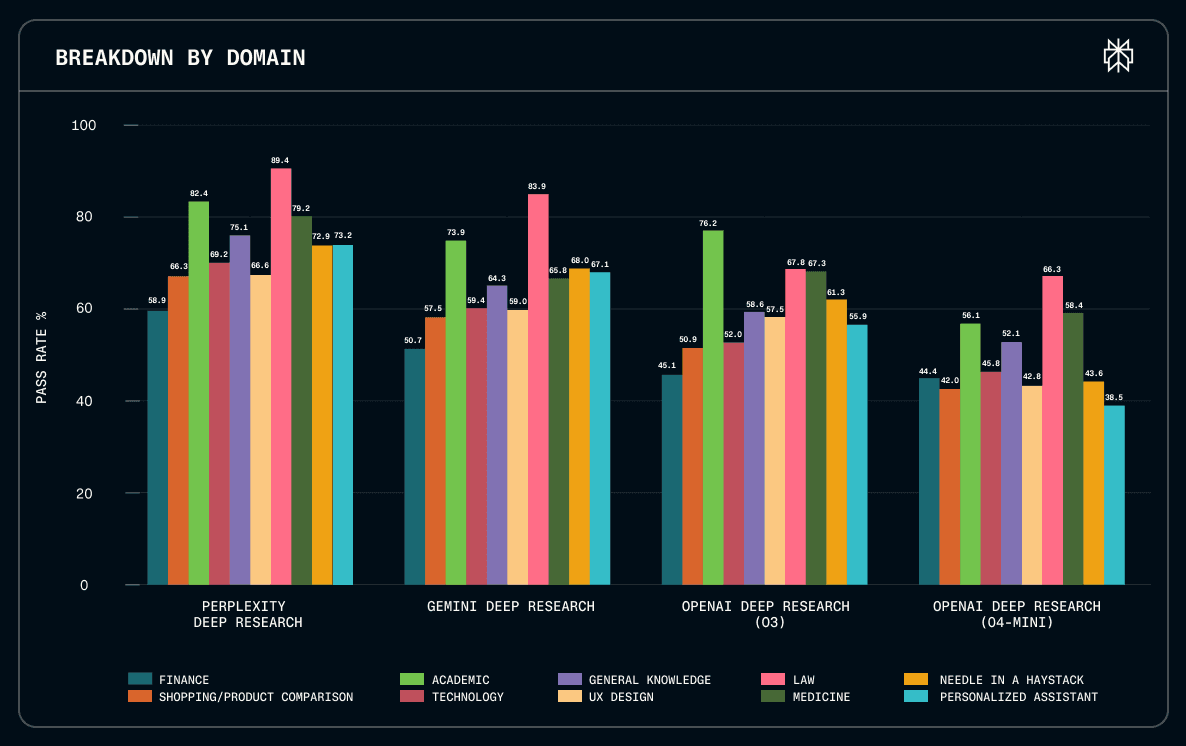
Performance by domain. We evaluated four deep research systems across 10 knowledge domains by measuring pass rates (percentage of evaluation criteria met). Deep Research achieved the highest pass rates across all domains, with particularly strong performance in Law (89.4%) and Academic (82.4%).
For users, this means more reliable answers whether you're preparing a legal brief, conducting a literature review, or comparing medical treatment options. Performance gaps widened significantly in complex reasoning tasks: in Personalized Assistant and Needle in a Haystack scenarios, Perplexity outperformed the lowest scoring system by over 20 percentage points. These domains mirror real user needs like personalized recommendations and finding specific facts buried in large documents.
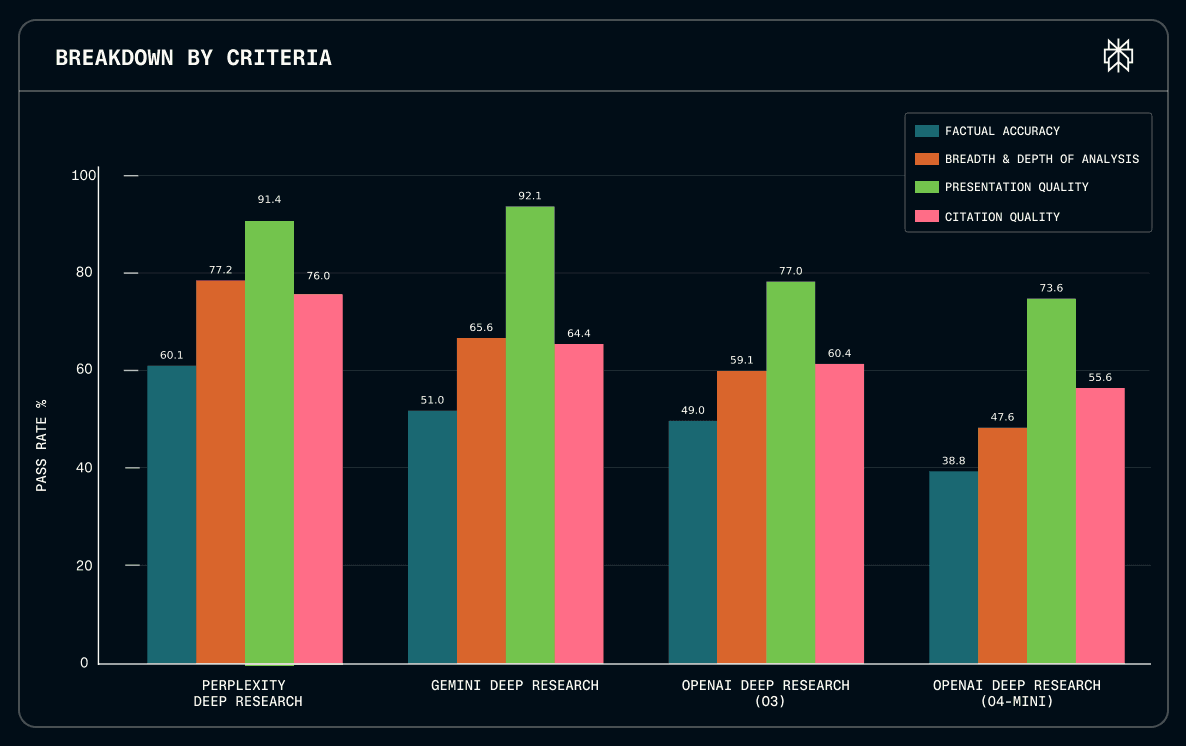
Performance by evaluation aspect. Across four key evaluation dimensions, Deep Research led in three: Factual Accuracy, Breadth and Depth of Analysis, and Citation Quality. These are the dimensions that matter most when you need to trust your research for real decisions, whether you're advising a client, making an investment, or writing a report with your name on it. Only one other system showed comparable performance to Perplexity Deep Research on Presentation Quality, indicating that the hard problems in deep research aren't about formatting but about getting the facts right and the analysis complete.
Quality and efficiency. Notably, the top performing system also achieved the lowest latency (459.6 seconds vs. 592 to 1808 seconds for competitors). For users, this means you don't have to choose between thorough research and getting answers quickly. This reflects the advantage of vertically integrated, end to end infrastructure: better search¹ [footnote link to our search api] and browser integration with optimized execution environments translate directly to faster, more accurate research.
What's next
Perplexity’s Deep Research harness is model agnostic: as stronger agentic LLMs emerge, we will rerun evaluations and publish updated results. And as we ship improvements to Deep Research on Perplexity.ai, users will see those gains reflected in both product performance and benchmark scores.
The benchmark currently evaluates English only, single turn interactions across ten domains. Future iterations will expand linguistic diversity, add multi turn evaluation, and broaden domain coverage.
Build better research agents with DRACO Benchmark
DRACO Benchmark is fully open source now. Any team building deep research systems can assess their models against real world research tasks rahter than synthetic academic puzzles. We're releasing the complete benchmark, all rubrics, and the judge prompt.
To learn more about methodology and detailed results, read the full technical report: DRACO benchmark and explore the dataset on Hugging Face.