How AI Agents Reshape Knowledge Work
Computer raises task autonomy, lowers cost, and widens the scope of work users take on.

Frontier AI systems are closing the gap between model intelligence and real-world utility. New models, compute architectures, and orchestration patterns are enabling these systems to accomplish tasks deemed impossible just a few months ago.
This rapid innovation has proved a boon to AI users by magnifying their leverage and agency. Yet it has also created a lag between the technological frontier and our understanding of precisely how knowledge work is evolving in response. How does frontier AI change the nature of knowledge work across professions? Which structural and economic transformations in this work might we expect?
We seek to close this gap through careful empirical analysis of Perplexity usage. Today, in collaboration with Harvard Business School researchers, we're sharing our first comprehensive study of Perplexity Computer in real-world deployment. Our findings suggest that Computer expands both the breadth and depth of what users can accomplish, at lower cost. Computer users are getting more done, working at higher levels of abstraction, and crossing disciplinary boundaries to unlock value outside their own professions.
This article presents the highlights from our study. Detailed methodology and findings are available in our technical report.
Introduction
The first mainstream generative AI systems were conversational assistants that engage in dialogue with users. These assistants sit between intent and action. They answer questions, explain tradeoffs, and suggest next steps. The user then has to translate the answer into work: open the right tools, gather files, edit documents, check intermediate outputs, and decide what to do next.
Agents change that division of labor. A user specifies an outcome, and the system plans across tools, executes intermediate steps, asks for missing inputs when needed, and returns a finished deliverable. Agents shift AI usage from looking things up and synthesizing them to planning and carrying out tasks autonomously.
This arc animates Perplexity's own product progression. In 2022, we launched Search, which defined the answer engine category by empowering users to ask questions and receive answers supported by verifiable citations across billions of documents. In 2025, we introduced the Comet browser, with an embedded web agent that reasons and acts alongside users on the open web. And in 2026, we launched Computer, a general-purpose agent orchestrator that autonomously works toward user-specified objectives across complex environments and lengthy time horizons.
How is this transition changing the way we work? We explore this question using data from our Search and Computer products, focusing on three dimensions:
Autonomy: how much autonomous work does Computer perform versus Search on the same task?
Efficiency: how much time and labor cost does Computer save relative to Search on the same task?
Scope: how does Computer change the kind of work users attempt?
We find that agents such as Computer require more upfront user effort (since users must specify the objectives to be delegated and review the results) but much less human effort per unit of work (due to more autonomous execution). That makes them especially effective on long, multi-step workflows. The payoff is work that is both deeper and cheaper. Computer shifts user effort from manual execution to supervision, expanding the range of what users can accomplish both within and outside their own areas of expertise.
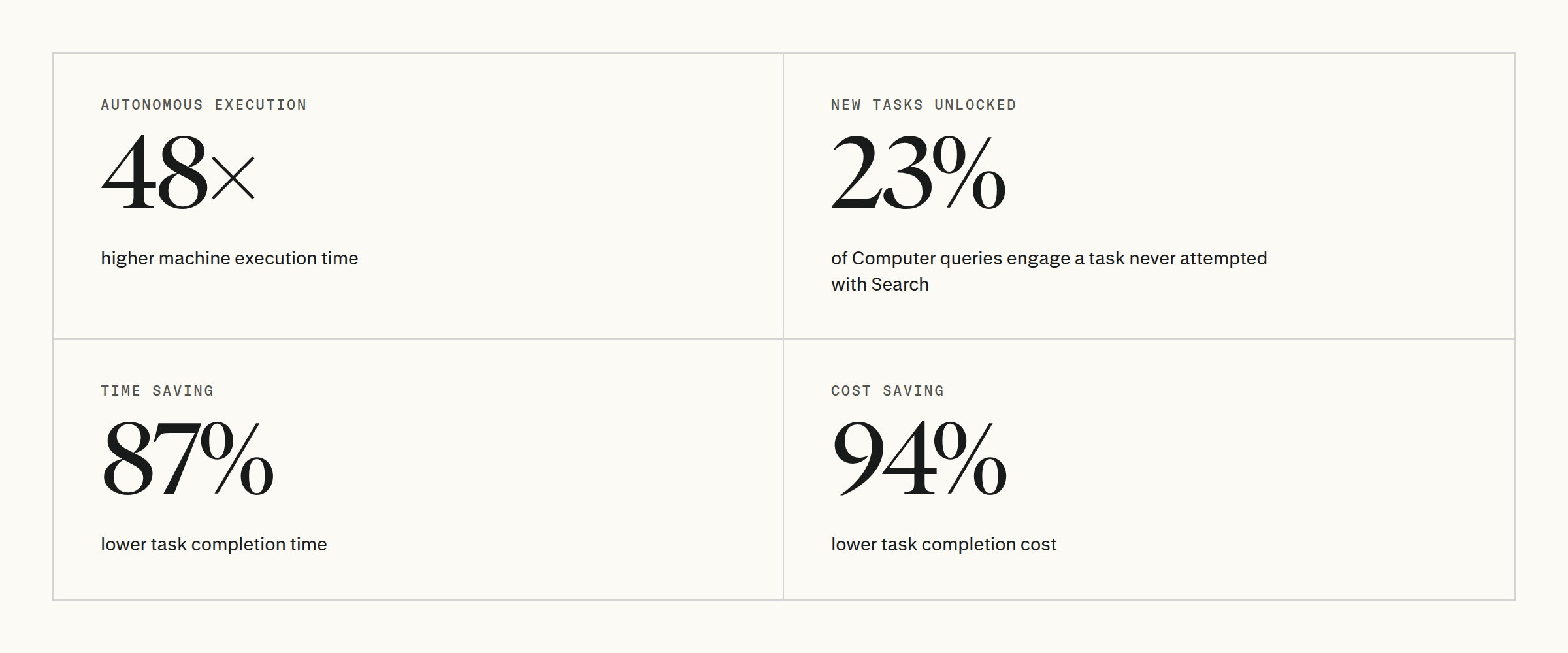
Computer Adoption and Use Cases
Computer was launched on February 25, 2026, and grew quickly in the first three months.
Cumulative Computer queries reached 84× their first-week total by May 27. As a baseline, cumulative Search usage among Computer users reached 14× its first-week total, higher than the 12× growth for non-Computer users.
Even after matching Computer and non-Computer users on subscription tier, primary Search topic, and prior Search intensity, a difference-in-differences comparison shows that adopting Computer increases Search use: Computer users make 1.05 more Search queries per day than similar non-Computer users.
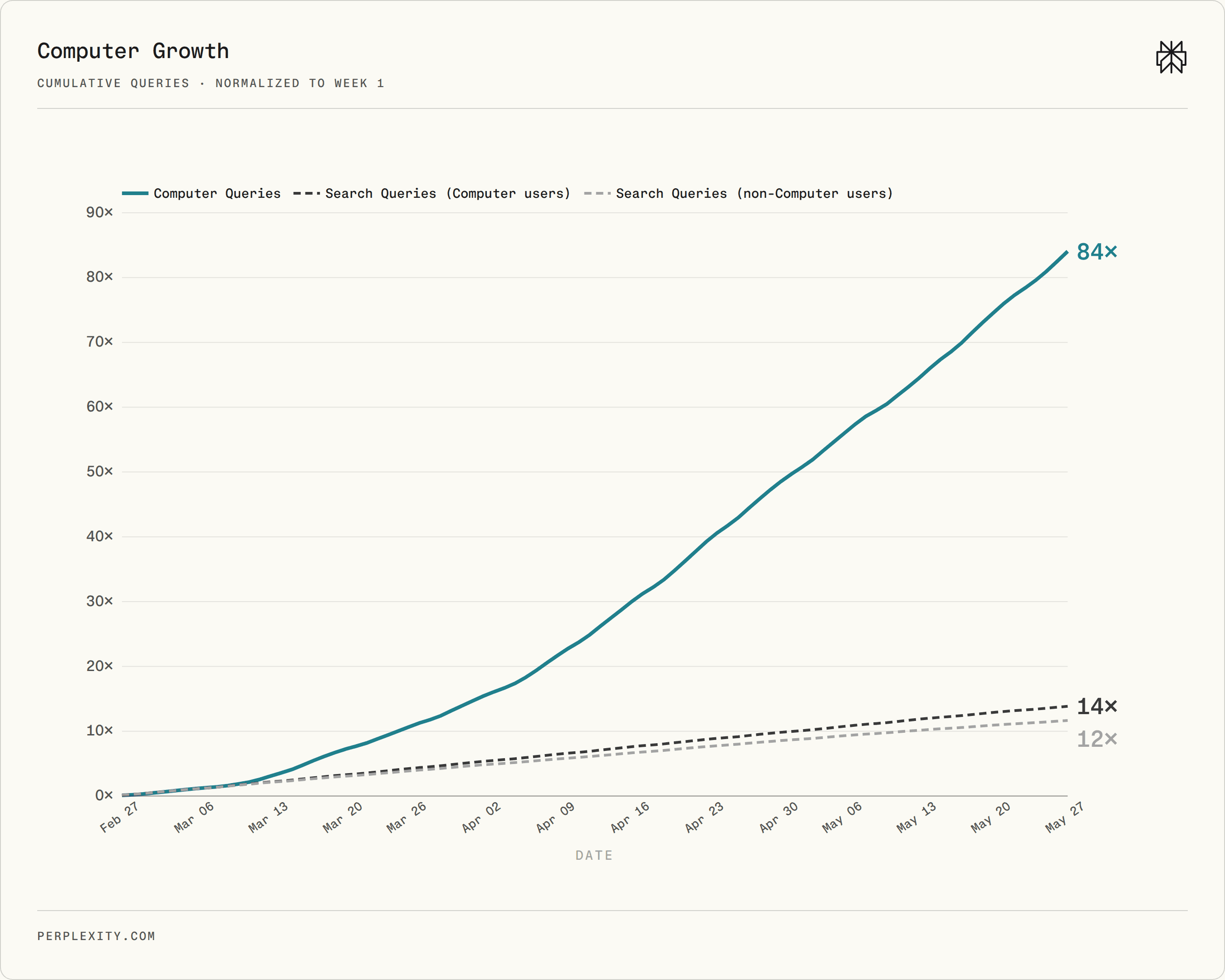
Cumulative growth indexed to each series' first week. Computer query volume reached 84× its first-week cumulative total during the February 27–May 27 window.
In a random sample of 100,000 Computer queries, Research and Analysis was the largest task category at 25.8%, followed by Document and Asset Creation at 18.6%. The observed task mix skews toward generative work: documents, spreadsheets, codebases, websites, and workflows that require work across multiple tools.
Turning to domains, use was broadly distributed across Software and IT, Finance and Investing, Marketing and Sales, Business Operations, Healthcare, Education, Legal, and Media.
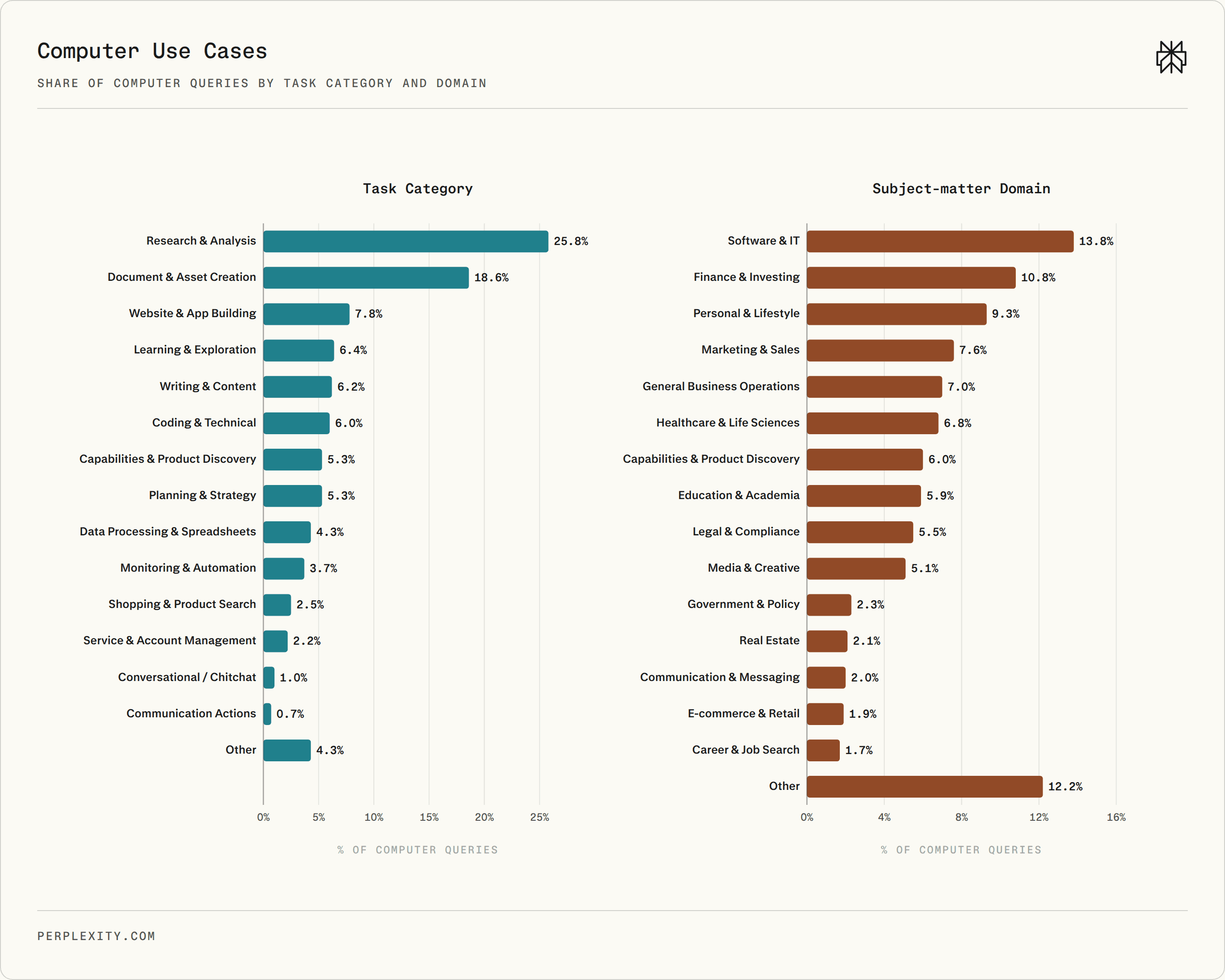
Computer use cases across task categories and subject-matter domains. Research, analysis, document creation, software, finance, business operations, and personal workflows all appear prominently.
Higher Autonomy and Quality
The most direct signal of autonomy is how long the system runs without human intervention after the user submits a request. Search usually returns a response in seconds. Computer often keeps working for minutes or even hours: searching, browsing, writing, editing, running code, and checking intermediate results.
We use Search and Computer sessions with near-identical initial queries as a proxy for the same task attempted with both products. Across 10,000 matched pairs, Computer performs 26 minutes of machine execution per session on average, versus 33 seconds for Search. That is a 48× increase in machine work on effectively the same tasks. At the median, the gap is 9 minutes versus 14 seconds, or 40×. The domain split shows the same pattern: Computer performs roughly 26–75× more machine work across all 18 domains.
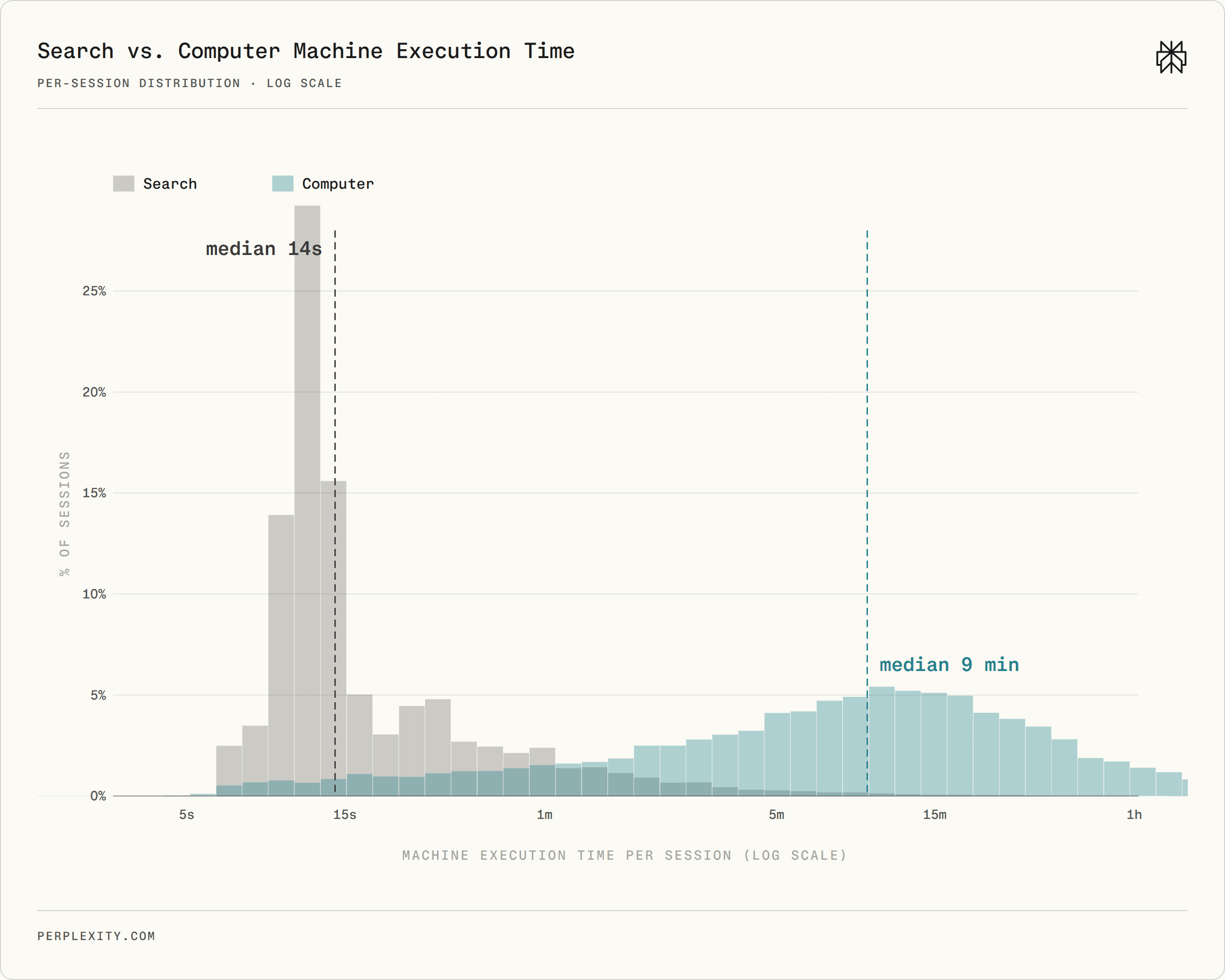
Per-session machine execution time for matched Computer and Search sessions. Search is concentrated near short response times; Computer has a wider distribution centered around long-running autonomous execution. Computer's mean execution time (26 minutes) is much higher than the median (9 minutes), indicating a long tail of complex, long-horizon requests.
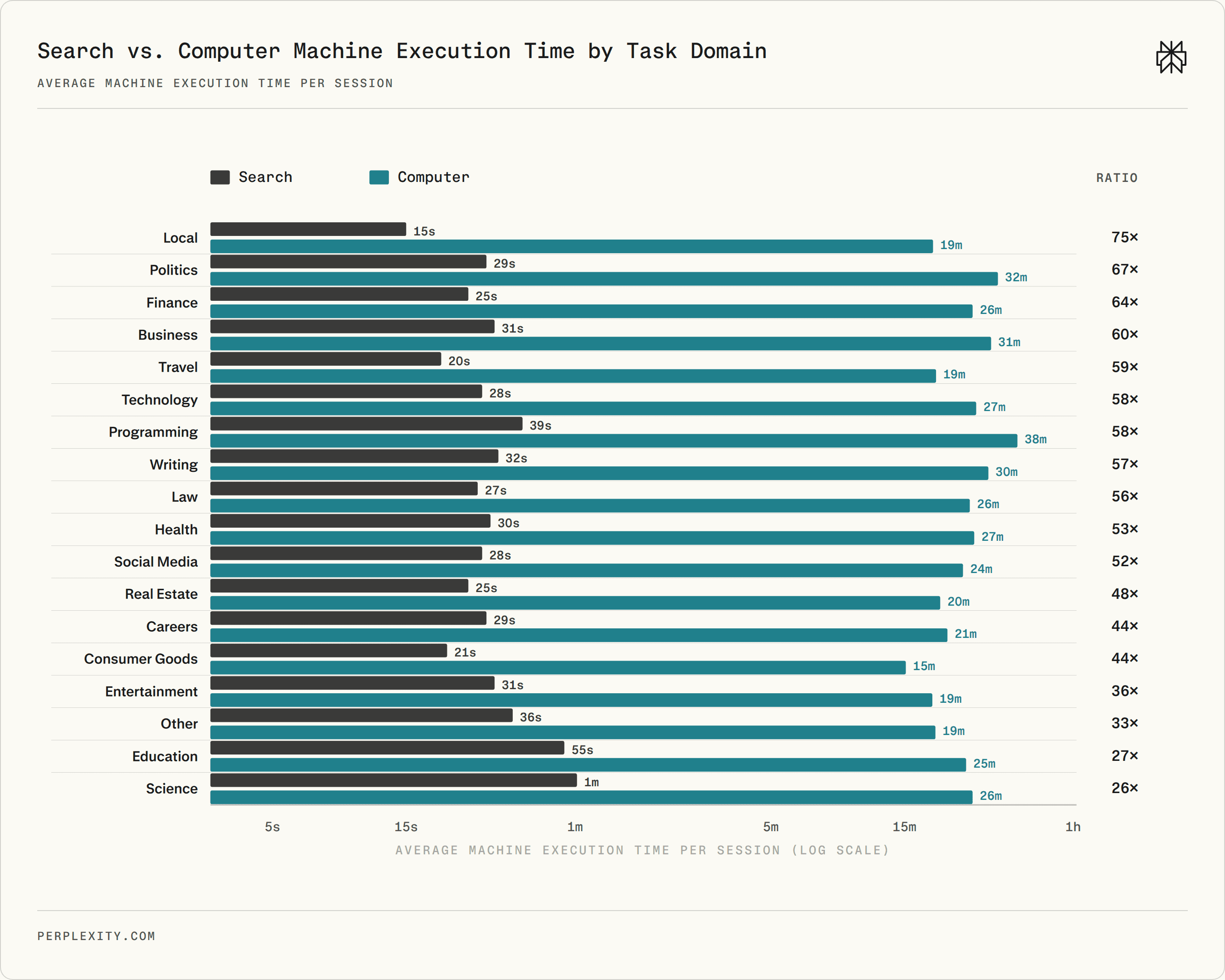
Average machine execution time by domain. Computer performs much more work per session because each user turn triggers downstream execution rather than only a conversational response.
Longer-running autonomy did not translate into more abandonment. User stop events were similar across products: 3.7% of Computer sessions and 3.4% of Search sessions contained at least one user stop event. Computer did pause for user input more often: 13% of Computer queries invoked at least one pause-for-user tool versus 0.3% for Search, usually to request approval or ask clarifying questions. That is the expected pattern for an agent: it can proceed autonomously most of the time, but it needs checkpoints to get permission and confirm what the user wants.
Computer also chains far more external tool calls—through the Model Context Protocol (MCP) or Application Programming Interface (API) endpoints—into a single session, doing work that a Search user would otherwise do by hand across separate apps. 7.9% of Computer sessions make at least one connector call versus 1.8% of Search sessions (a 4× gap), and Computer averages 1.19 connector calls per session versus 0.10 for Search (a 12× ratio). In other words, Computer doesn't just run longer; it reaches across more of a user's connected services to pull data and take actions.
Follow-up behavior also changes in composition. In a 1,000-pair multi-turn sample, the overall propensity toward task advancement is nearly identical across products (52.7% of Computer follow-ups versus 52.9% for Search), but what users ask for shifts: because Computer returns a more complete deliverable up front, its users substitute extensions for clarifying drill-downs (extensions 14.2% versus 12.5%; drill-downs 22.0% versus 23.4%). Computer users also spend slightly more of their follow-ups reviewing and revising output (24.6% versus 23.6%), while Search is heavier on short directives such as confirmations, retries, and format requests (11.6% versus 9.9%) that Computer folds into its initial run. In other words, Search creates shorter digest-and-execute loops; Computer creates longer review-and-extend loops.
Most importantly, quality did not fall with higher autonomy. On matched multi-turn sessions, meaningful next-turn dissatisfaction was 1.3% for Computer versus 2.9% for Search, a 55% reduction. Any dissatisfaction, including mild signals, was 10.8% for Computer versus 16.6% for Search.

Next-turn dissatisfaction signals in the matched multi-turn sample. Columns may not sum exactly to 100% due to rounding.
Efficiency Gains from Autonomy
Higher autonomy swaps manual human work for machine computation, which raises efficiency. To quantify this effect, we compare two setups on the same matched tasks.
Search + Human: Search handles retrieval and synthesis; the human manually executes.
Computer + Human: Computer performs the workflow; the human scopes the task and reviews the output.
We can't directly observe how long a task would take a human, so we triangulate with three independent estimates:
Tool-based estimate: We classify Computer tool calls into two categories: "Search" and "Do." Search tools correspond to information retrieval and synthesis steps that are already handled by the Search product. Do tools represent execution steps that a human would need to perform manually when using Search alone. We then estimate the time required for an experienced human to carry out these Do actions.
LLM-based estimate: We feed queries from Computer sessions into an LLM to estimate the time required for a skilled professional who receives answers from Search but must perform all execution steps manually.
User-reported estimate: We conduct 25 semi-structured interviews with active Computer users across domains and elicit pre-Computer workflows and the time those workflows would have taken.

Tool classification used in the tool-based estimate. "Search" tools mirror capabilities Search already provides, so no manual time is charged. "Do" tools require the human to act on Search's research output; per-call minute estimates approximate the time a skilled professional would spend performing the equivalent action manually.
Under the tool-based estimate, the average Search + Human task takes 269 minutes, while the corresponding Computer + Human workflow takes 36 minutes. That is an 87% reduction in task time.
To translate task time into cost, we use domain-specific average hourly wages from U.S. Bureau of Labor Statistics Occupational Employment and Wage Statistics (BLS OEWS) May 2025 data (U.S. Bureau of Labor Statistics 2026). Combining model cost with domain-specific human labor cost, Computer reduces estimated task cost by 94% on average.
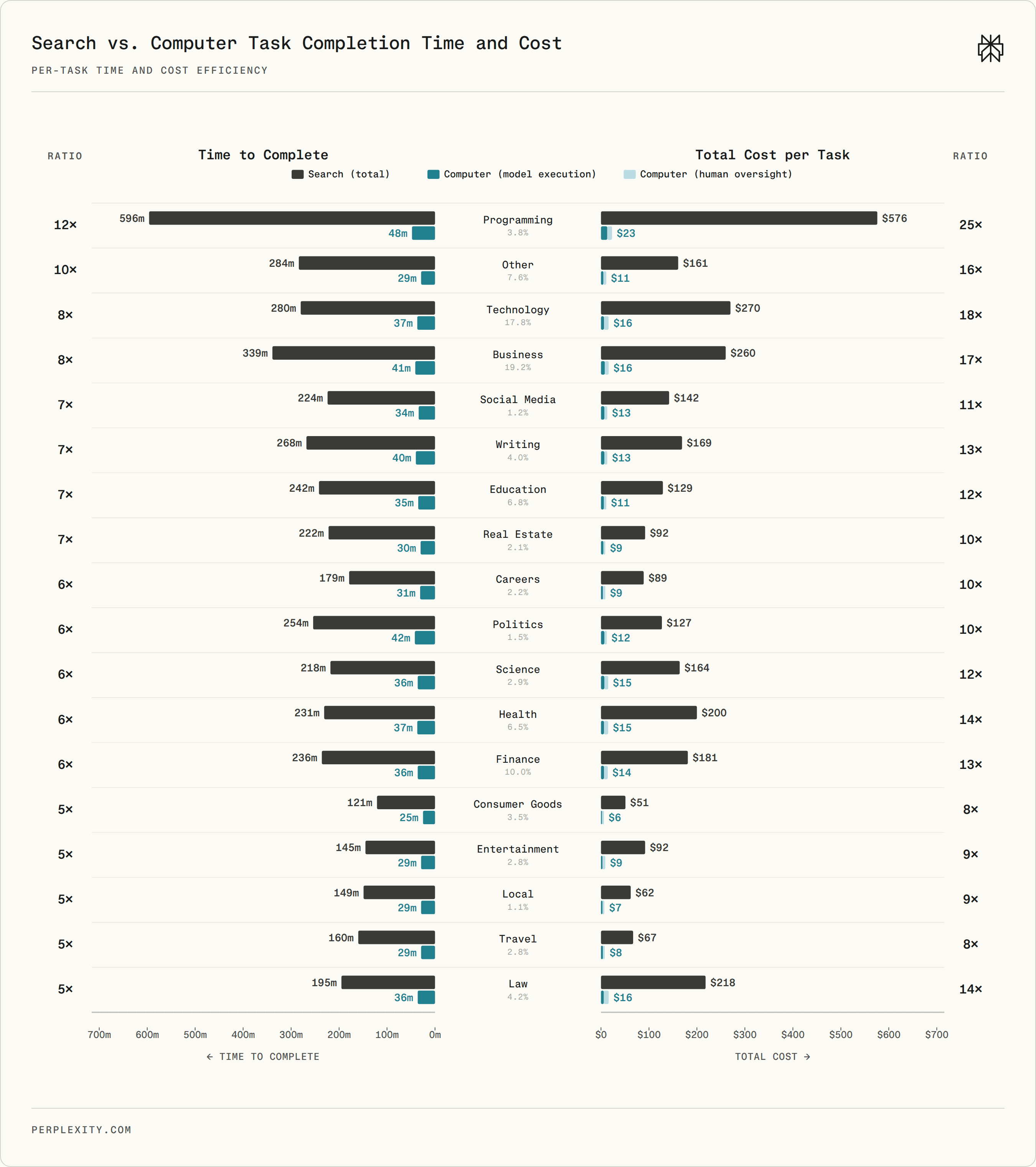
Estimated task time and cost for Search + Human versus Computer + Human. Human labor dominates the Search + Human baseline, while Computer shifts much of the work to model and tool execution.
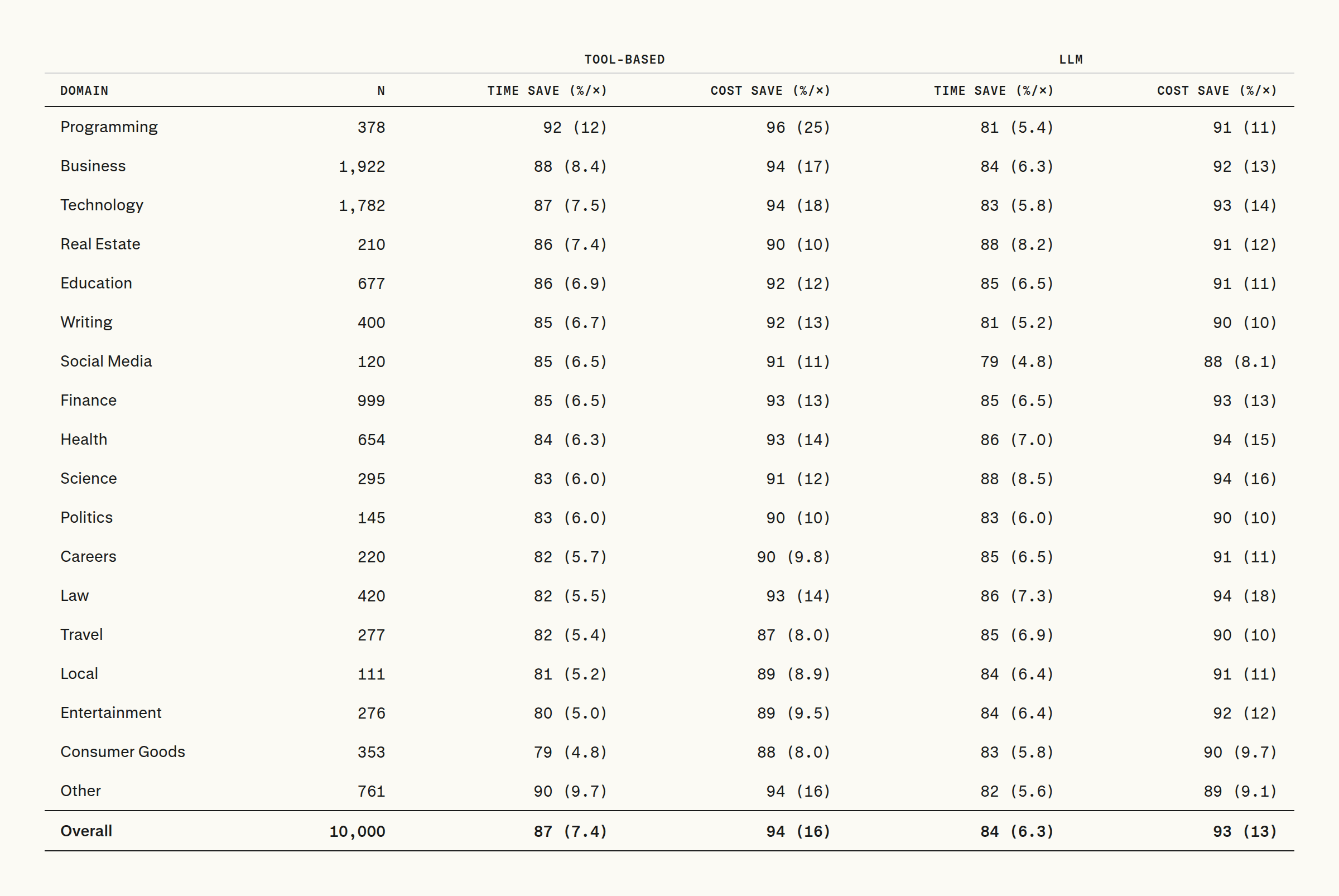
Percentage of time and cost saved by Computer + Human relative to Search + Human, with multipliers in parentheses (e.g., 94% (16×) means Computer + Human is 94% or 16 times cheaper). Human labor cost uses BLS OEWS May 2025 mean hourly wages.
The efficiency advantage appears across all 18 domains, with 79–92% time savings and 87–96% cost savings. Programming is the most extreme case: 596 minutes for Search + Human versus 48 minutes for Computer + Human—a 92% time reduction that yields a 96% cost reduction. Business, Technology, Education, and Writing also show large gains. Time savings tend to translate into greater cost savings in higher-wage domains.
How robust is this result? Consider a breakeven: for Search + Human to match the cost of Computer + Human, a professional would need to finish every manual step in 14–24 minutes (median 18). Computer keeps its edge across every domain even under more conservative assumptions: for instance, an 8× overestimate in per-tool time, or a 12× underestimate in Computer's oversight time.
The LLM-based estimate yields similar aggregate results: an 84% reduction in time and a 93% reduction in cost overall. User interviews show a much wider range of outcomes—from 5× to over 300× speedups—likely reflecting substantial variation in users' pre-Computer baselines. The median speedup across participants is 25×, corresponding to a 96% reduction in time.
Task Scope Expands Horizontally and Vertically
Speed and cost on matched tasks capture only part of the story. The shape of work could also change. As Computer replaces manual execution with machine computation, users may take on different kinds of work—tasks that cross occupational boundaries and those that require higher levels of expertise.
First, we ask whether users work outside their inferred primary occupation cluster more often with Computer than with Search. Second, we compare Computer and Search queries from the same users using five task-level classifications: Bloom's Revised Taxonomy (Anderson and Krathwohl 2001), abstract versus routine work in the task-content tradition (Autor, Levy, and Murnane 2003), O*NET Knowledge breadth (National Center for O*NET Development 2026), O*NET work-activity breadth, and new tasks that were not attempted with Search.
The horizontal shift is apparent in the data. Across a sample of 8,000 users from eight occupation clusters, using all of their queries, Computer users work outside their primary occupation 59% of the time, compared to 50% for Search. The largest increases appear in Management and Entrepreneurship, Digital Technology, Arts and Design, and Healthcare and Human Services. Cross-occupation Search queries are concentrated in Digital Technology, whereas Computer queries delegate work that crosses into more diverse domains where users would otherwise need specialists.
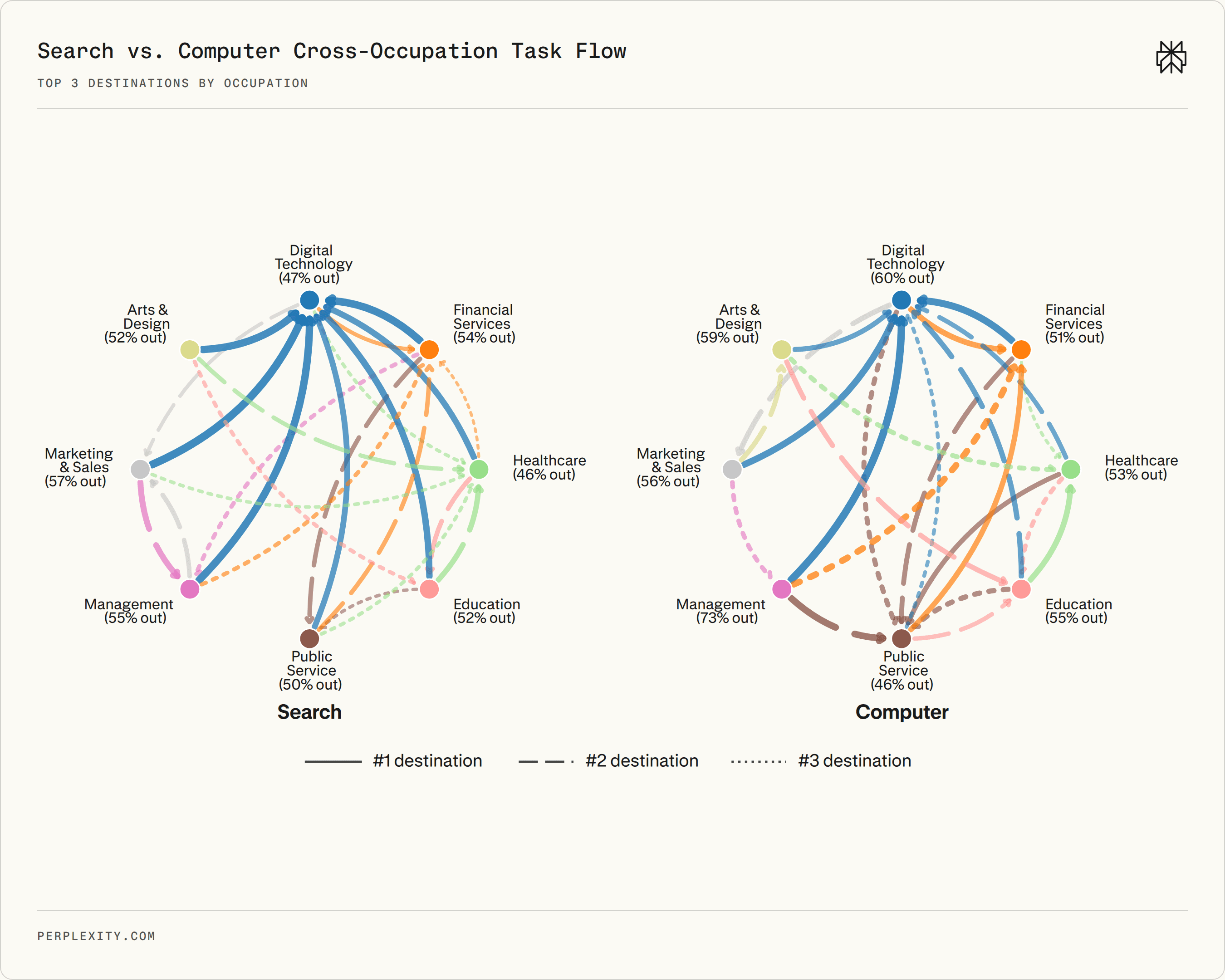
Cross-occupation task flows across the eight occupation clusters. Curved arcs show each cluster's top outgoing destinations, with line width proportional to destination share and line type indicating the rank. Search concentrates cross-occupation flows into Digital Technology, while Computer spreads flows across Marketing, Management, Financial Services, and other executional destinations.
The vertical shift is even larger. In a sample of 5,000 Computer queries and 5,000 Search queries from the same set of dual-product users, Computer queries are more cognitively complex than Search queries. On Bloom's Revised Taxonomy, 76% of Computer queries require higher-order cognition, compared to 55% for Search. The difference is concentrated at the top: 50% of Computer queries are Create-level tasks, compared to 26% for Search. Search has much more mass at Remember-level factual lookup. On the abstract-versus-routine task-type dimension, 71% of Computer queries involve abstract, non-routine cognition versus 53% for Search.
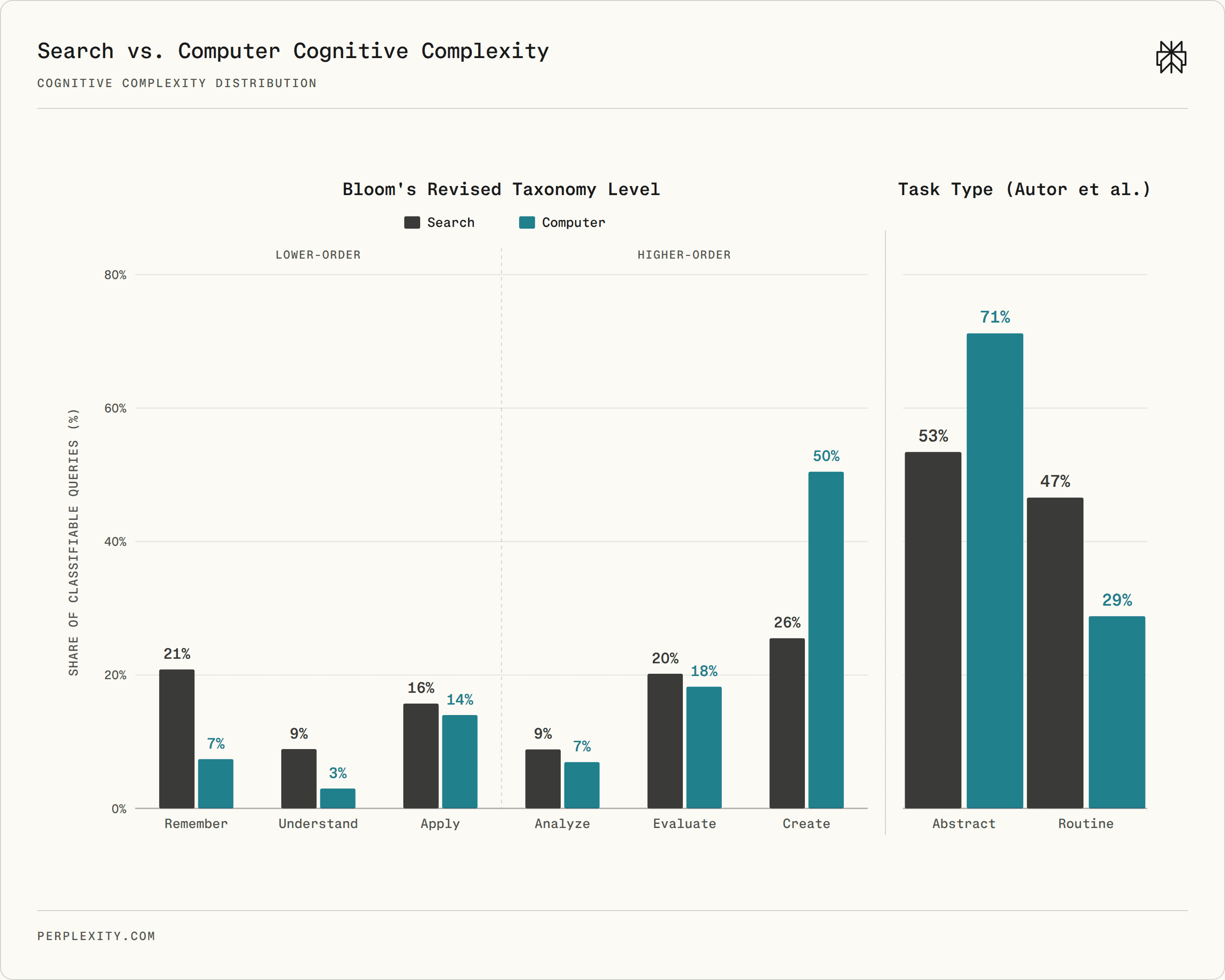
Cognitive complexity of Computer and Search queries. Computer shifts strongly toward Create-level and abstract non-routine work.
Computer tasks also draw on more knowledge domains. The average Computer task requires substantive expertise in 2.40 O*NET Knowledge areas, compared to 1.74 for Search, a 38% increase. Computer is nearly three times as likely as Search to require three or more knowledge domains: 51% versus 17%.
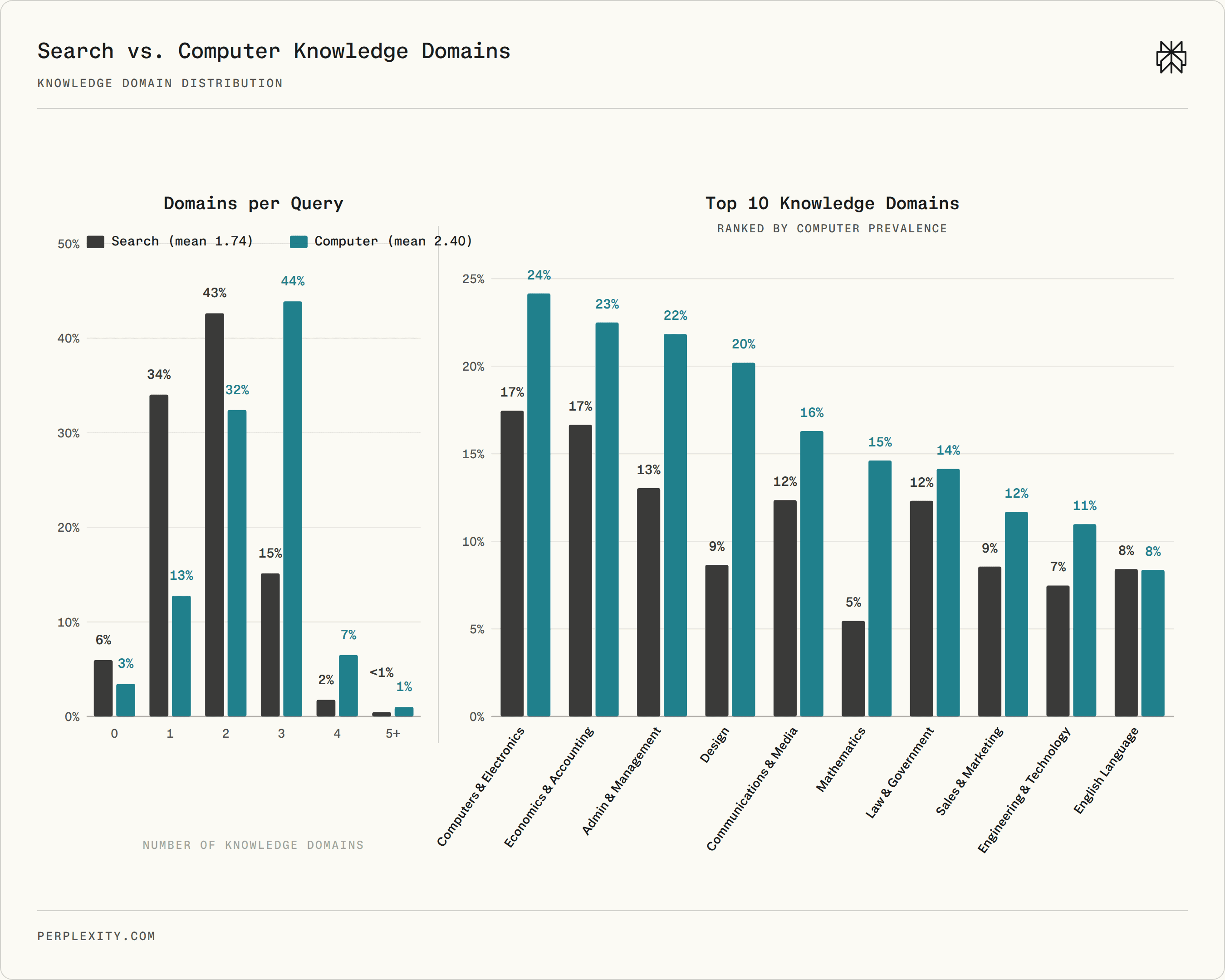
Required knowledge domains per query. Computer sessions concentrate at two to three domains and are much more likely to require broad expertise.
At the work-activity level, the same pattern holds. A typical Computer query engages 2.95 O*NET Generalized Work Activities and 4.01 Intermediate Work Activities versus 2.24 and 2.87 for Search, a 32% and 40% increase. At finer levels, Computer engages 59% more Detailed Work Activities and 60% more occupation-specific Task Statements.
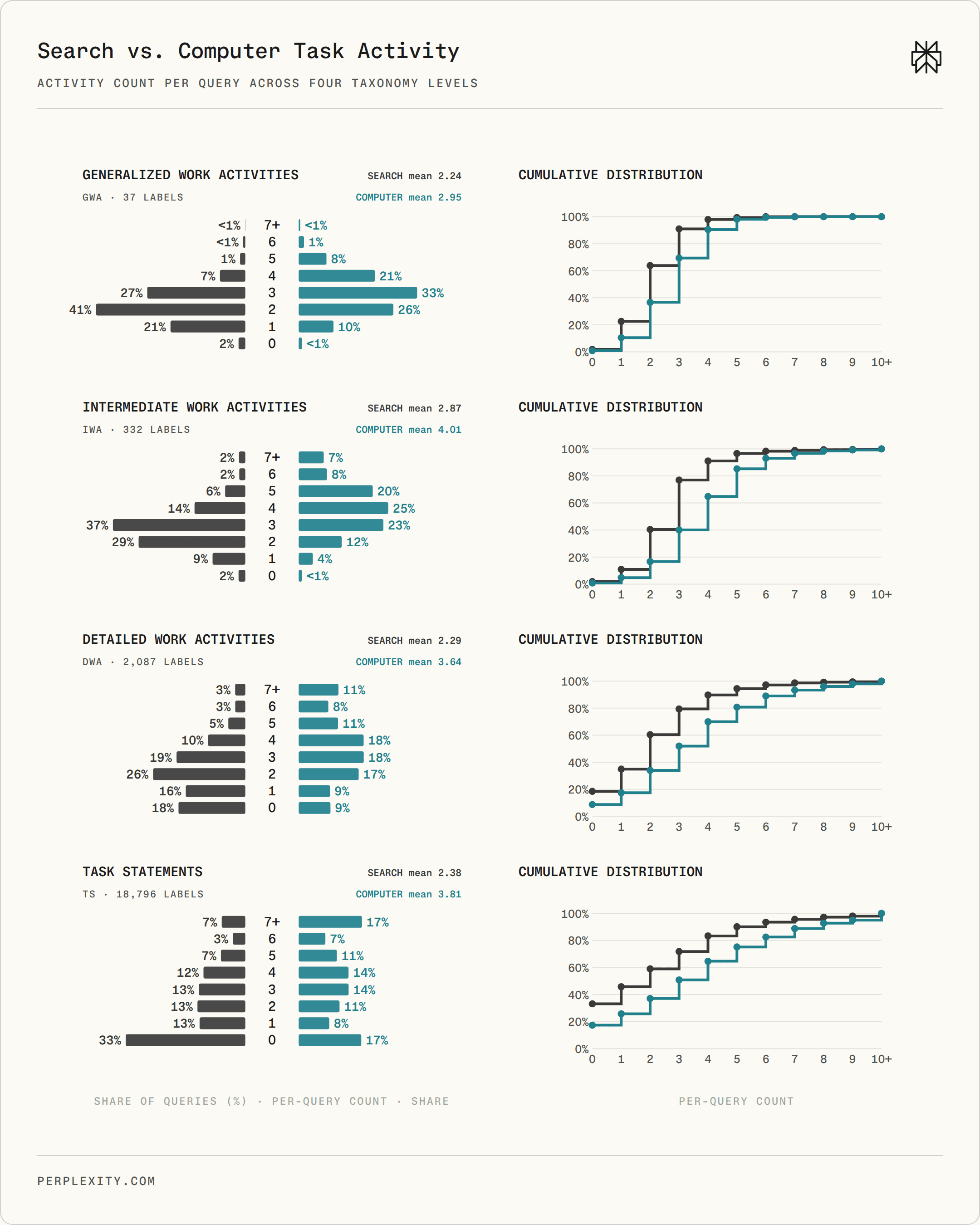
Per-query task-activity breadth across O*NET nesting levels. Computer shifts the distribution right at the intermediate, detailed, and task-statement levels.
The most revealing measure is the set of tasks that appear in Computer but not in Search among the same users. At the strictest definition, where a task statement appears in Computer and never appears in the paired Search sample, 23% of Computer queries engage at least one Computer-only task statement. Relaxing the threshold to allow up to five Search occurrences raises the share to 38%, and it plateaus near 41%. These Computer-only activities concentrate in software and web development, documentation production, and data visualization or graphics. That is exactly where autonomous execution matters most: Search explains; Computer produces.
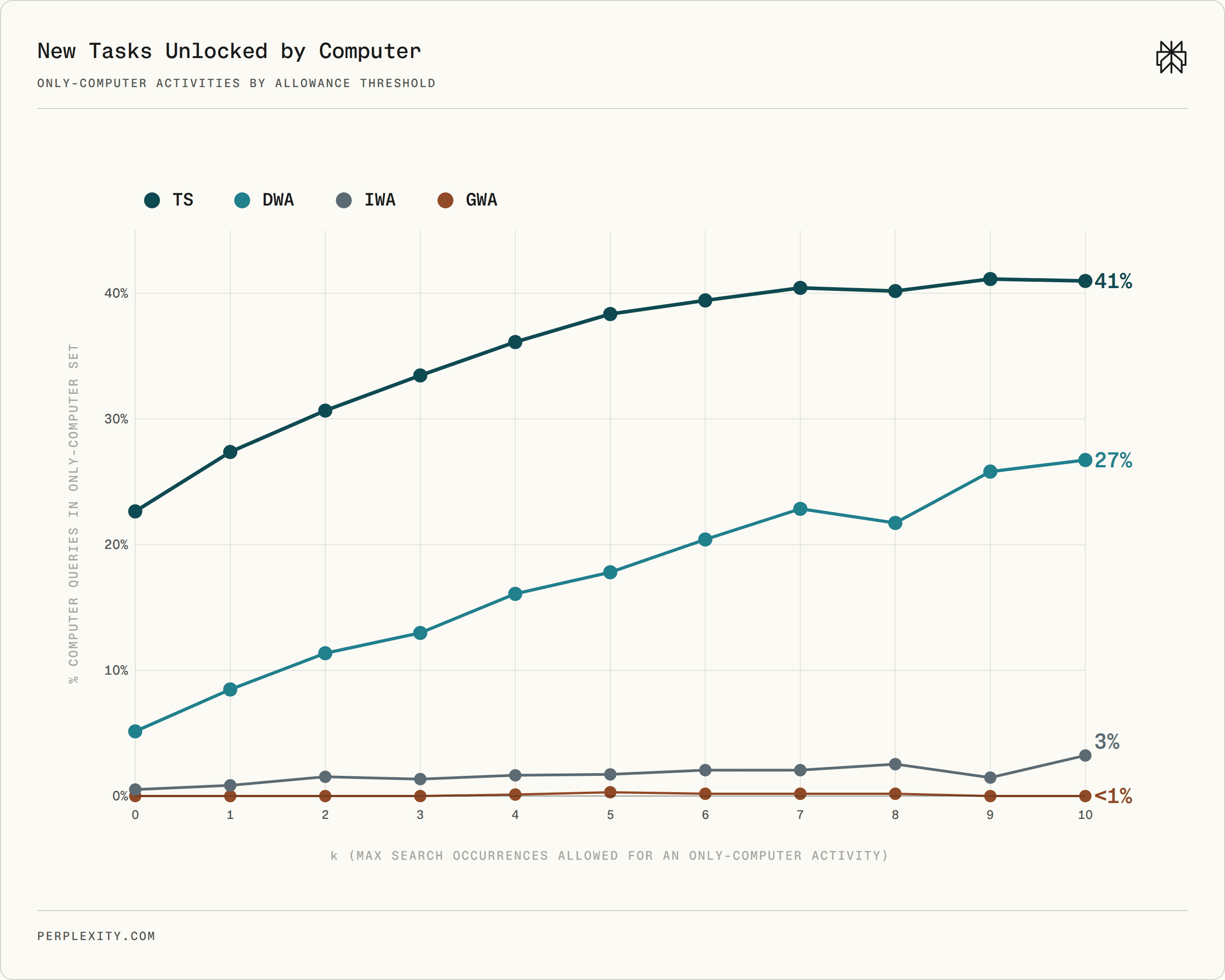
Share of Computer queries that engage at least one Computer-only O*NET activity under different occurrence thresholds. The strongest separation appears at the fine-grained task-statement level.
Discussion
Most evidence on AI at work focuses on the assistant setting. That literature has shown large productivity gains in augmenting writing, customer support, coding, and consulting (e.g., Noy and Zhang 2023; Brynjolfsson, Li, and Raymond 2025; Cui et al. 2026; Dell'Acqua et al. 2026).
Agents change user behavior and downstream economic outcomes. Production deployments are beginning to reveal agent usage and impact in real-world settings but are mostly focused on specialized coding agents and early browser agents (e.g., Sarkar 2026; McCain et al. 2026; Demirer, Musolff, and Yang 2026; Yang et al. 2025). We complement this work and bridge the assistant and agent literature by comparing user interaction with a general-purpose agent orchestrator versus a conversational assistant, and by extending downstream impact analysis to a wider range of knowledge work.
We also move from exposure to realized task recomposition. Prior work estimates which occupations are exposed to AI using task descriptions and occupational structure (e.g., Eloundou et al. 2024; Felten, Raj, and Seamans 2023), while usage-based measures show the gap between exposure and deployment (Massenkoff and McCrory 2026). We document how the task composition shifts with agent access.
We note several caveats. First, the observation window is early, and early adopters skew toward AI natives. Users are also actively experimenting and adapting their workflows within a rapidly evolving product landscape, so these patterns may shift over time. Second, the session-based matched-query design leaves out many Computer tasks that have no close Search equivalent. While sessions provide a natural way to segment tasks, users do not always follow this structure in practice, making sessions a noisy proxy for task units. Third, the efficiency estimates depend critically on assumptions about human-equivalent tool time and human oversight time. Although LLM-based estimates and user interviews point in the same direction, and breakeven and sensitivity analyses indicate robustness, the exact magnitudes should be read as approximate. Relatedly, LLM classification error introduces additional measurement noise. Finally, we observe user behavior only within the Perplexity ecosystem and do not capture activity outside it, which may limit our view of users' full work activities and tool use.
Looking Ahead
Agents make existing tasks faster and cheaper—and, more importantly, make tasks spanning occupational boundaries and expertise levels viable.
When a system can search, browse, code, edit files, connect to services, and produce deliverables, the user's bottleneck shifts. They spend less time operating the workflow and more time specifying goals, supplying context, checking outputs, and asking for extensions. The user moves from operator to supervisor.
At the individual level, this shift expands the task frontier, enabling users to take on work that is both broader and deeper. At the organizational and labor market level, how these micro-level changes aggregate remains an open question. If a single individual, equipped with agents, can complete workflows that previously required multiple roles, then the long-run impact of agents will not be captured by speed and cost metrics alone. Instead, it will manifest in how work is bundled, how roles are defined, and how teams are structured.
To learn more about our methodology and findings, read the full technical report.
References
Anderson, Lorin W., and David R. Krathwohl. 2001. A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom's Taxonomy of Educational Objectives. New York: Longman.
Autor, David H., Frank Levy, and Richard J. Murnane. 2003. "The Skill Content of Recent Technological Change: An Empirical Exploration." The Quarterly Journal of Economics 118 (4): 1279–1333.
Brynjolfsson, Erik, Danielle Li, and Lindsey R. Raymond. 2025. "Generative AI at Work." The Quarterly Journal of Economics 140 (2): 889–942.
Cui, Zheyuan Kevin, Mert Demirer, Sonia Jaffe, Leon Musolff, Sida Peng, and Tobias Salz. 2026. "The Effects of Generative AI on High-Skilled Work: Evidence from Three Field Experiments with Software Developers." Management Science, Articles in Advance.
Dell'Acqua, Fabrizio, Edward McFowland III, Ethan R. Mollick, Hila Lifshitz-Assaf, Katherine Kellogg, Saran Rajendran, Lisa Krayer, François Candelon, and Karim R. Lakhani. 2026. "Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of Artificial Intelligence on Knowledge Worker Productivity and Quality." Organization Science, Articles in Advance.
Demirer, Mert, Leon Musolff, and Liyuan Yang. 2026. "Writing Code vs. Shipping Code: Productivity Effects Across Generations of AI Coding Tools." NBER Working Paper 35275.
Eloundou, Tyna, Sam Manning, Pamela Mishkin, and Daniel Rock. 2024. "GPTs are GPTs: Labor Market Impact Potential of LLMs." Science 384 (6702): 1306–1308.
Felten, Edward W., Manav Raj, and Robert Seamans. 2023. "Occupational Heterogeneity in Exposure to Generative AI." SSRN 4414065.
Massenkoff, Maxim, and Peter McCrory. 2026. "Labor Market Impacts of AI: A New Measure and Early Evidence." Anthropic.
McCain, Miles, Thomas Millar, Saffron Huang, Jake Eaton, Kunal Handa, Michael Stern, Alex Tamkin, Matt Kearney, Esin Durmus, Judy Shen, Jerry Hong, Brian Calvert, Jun Shern Chan, Francesco Mosconi, David Saunders, Tyler Neylon, Gabriel Nicholas, Sarah Pollack, Jack Clark, and Deep Ganguli. 2026. "Measuring AI Agent Autonomy in Practice." Anthropic.
National Center for O*NET Development. 2026. O*NET 30.2 Database. U.S. Department of Labor, Employment and Training Administration.
Noy, Shakked, and Whitney Zhang. 2023. "Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence." Science 381 (6654): 187–192.
Sarkar, Suproteem K. 2026. "AI Agents and Higher-Order Work." University of Chicago Booth School of Business.
U.S. Bureau of Labor Statistics. 2026. "Occupational Employment and Wage Statistics: May 2025 Estimates." U.S. Department of Labor.
Yang, Jeremy, Noah Yonack, Kate Zyskowski, Denis Yarats, Johnny Ho, and Jerry Ma. 2025. "The Adoption and Usage of AI Agents: Early Evidence from Perplexity." arXiv preprint arXiv:2512.07828.