Improving Unigram Tokenizer CPU Performance
We reimplemented our Unigram tokenizer from scratch as a focused performance project.

We reimplemented our Unigram tokenizer from scratch as a focused performance project. At production input lengths, the new encoder cuts p50 latency by roughly 5× versus the Hugging Face tokenizers crate, ~2× versus SentencePiece (C++), and ~1.5× versus IREE's tokenizer (C), with zero steady-state heap allocations. In production this reduced CPU utilization in our inference stack by 5-6× and shaved double-digit milliseconds off reranker latency.
Motivation
LLM inference cost is usually framed as GPU work: KV caches, attention kernels, expert routing. But a meaningful portion of production traffic runs on much smaller models, two to three orders of magnitude smaller than frontier transformers. Embedding models, classifiers, and rerankers still run on GPUs, but the forward pass is short enough that everything around it starts to matter.
The clearest case is a reranker scoring hundreds of candidate documents per request. With a small model, GPU compute typically finishes in single-digit milliseconds, but every input still has to go through CPU-side tokenization first, turning text into vocabulary IDs. When the batch is large, that can account for a meaningful fraction of total request latency.
This work targets XLM-RoBERTa, a 250K-token Unigram vocabulary trained with SentencePiece. Fine-tuned RoBERTa-family encoders are a common choice for ranking, retrieval, and similarity tasks. We report single-threaded per-encode latency throughout; in production we parallelize across cores using rayon.
Throughout this post we treat Hugging Face's tokenizers crate as the reference we benchmark against, since it is the default Rust tokenizer most teams reach for. SentencePiece (C++) and IREE (C) are included for comparison as the other two major production implementations.
The Viterbi Algorithm
Unigram tokenization, introduced by Kudo in 2018 (Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates) and shipped in SentencePiece, frames segmentation as a most-probable-path problem: each vocabulary token has a learned log-probability, and the encoder picks the segmentation whose token scores sum to the highest value. The problem is solved with the Viterbi algorithm (1967), with byte positions as graph layers and vocabulary tokens as edges spanning a contiguous byte range. The recurrence is a one-dimensional DP over byte positions:
The outer loop is linear in input length, bounded at each position by the longest vocabulary token (48 UTF-8 bytes for XLM-RoBERTa). The inner trie walk is the hot path: on a 16k-token input, it runs hundreds of thousands of transitions and retires tens of millions of instructions per encode.
Reference Implementation
Hugging Face's tokenizers v0.22 implements the recurrence directly, with a hash-map for the reverse lookup and hash-map-children at every trie node:
And the inner loop (simplified) – every prefix-search match allocates a fresh string and then probes the hash-map:
The code is readable Rust, but a lot of work happens that is invisible at the source level. The next section breaks down where the time goes.
A Note on Preprocessing
Before Viterbi runs, the input goes through Unicode normalization (NFKC) and word-boundary marking. Profiling puts preprocessing at less than 5% of total encode time in our scenarios, so we focus on the Viterbi forward pass for the rest of the post.
Where the Reference Implementation Spends Its Time
There are two ways to speed up CPU code: execute fewer instructions, or get higher IPC. Cachegrind measures the first, perf stat measures the second. Every optimization in this post lands on one or the other.
CPUs stall on four things: cache misses (L1d ~4 cycles, an L3-miss-to-DRAM is hundreds), dependent-load chains the out-of-order engine cannot parallelize, branch mispredicts (~15-20 cycles flushed per wrong guess), and allocator calls. The reference unigram engine implementation hits all four:
Bottleneck | Mechanism | Measured impact |
|---|---|---|
Allocation per match | String::from_utf8 on the matched bytes plus an AHashMap lookup per trie match; the token ID is already in the leaf, but the reference does not store it there | 7,295 allocs at 512 tokens, 14,542 at 1k, 299,171 at 16k |
Pointer chase per byte | An AHashMap at every trie node, hashing the next byte and dereferencing two pointers per step; the Node struct also bundles cold fields like is_leaf, pulling them into cache on every visit | L1d miss rate stays low (~2.5% at 1k) because allocator hot pages live in L1; the cost shows up as dependent-load latency |
L2 thrashing on long inputs | DP table, prefix scratch, and the output token list are all freshly allocated each call | L2 miss rate climbs from 12% at 128 tokens to 50% at 16k as the cumulative alloc footprint exceeds the per-core 2 MB L2 |
The dominant cost is the allocation per match. At 1k tokens, the reference implementation retires (completes) roughly 7M instructions per encode at IPC of 2.8, most of them in allocator calls and string conversions. L2 misses only matter past ~1k tokens, once the cumulative allocation footprint overflows per-core cache.
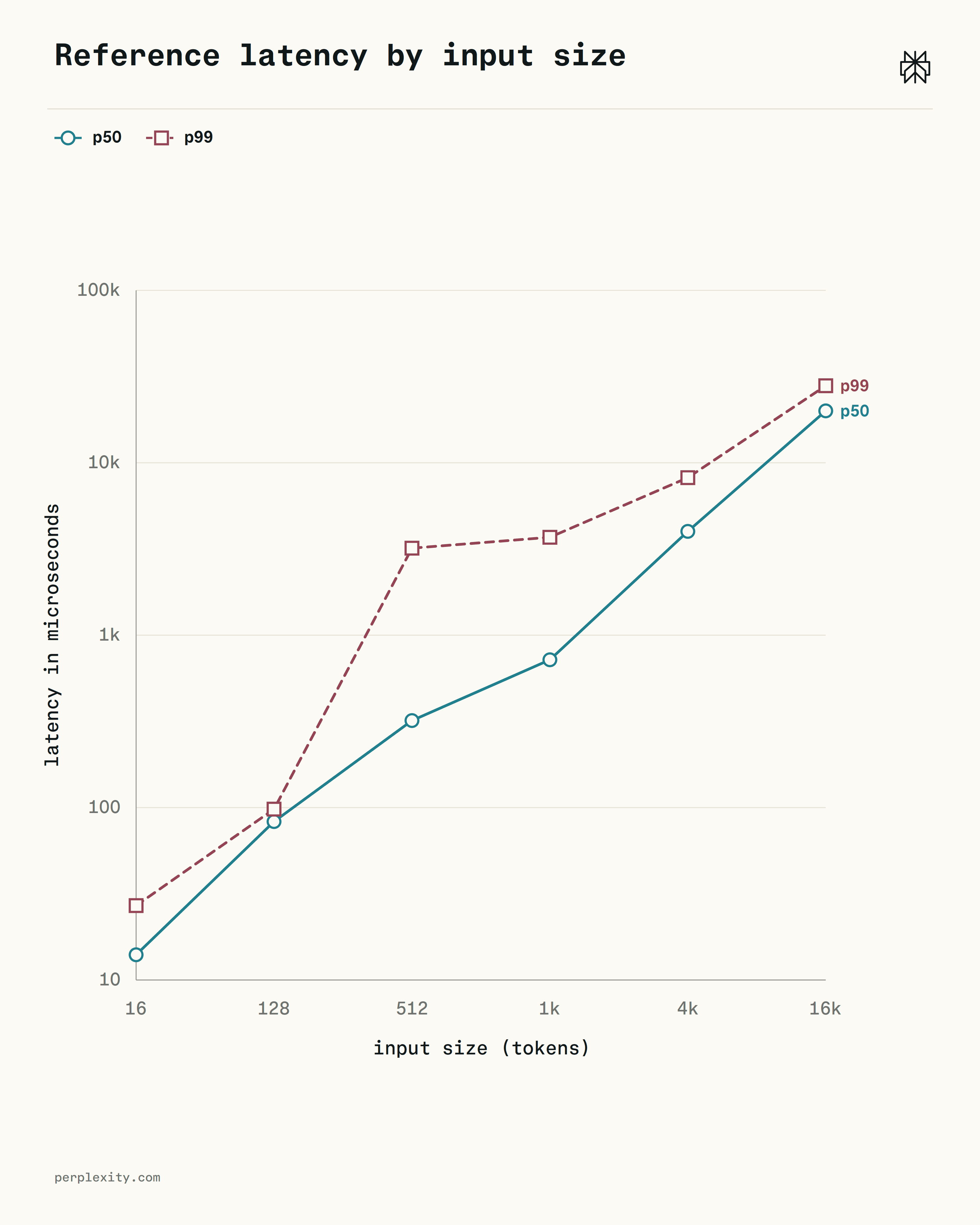
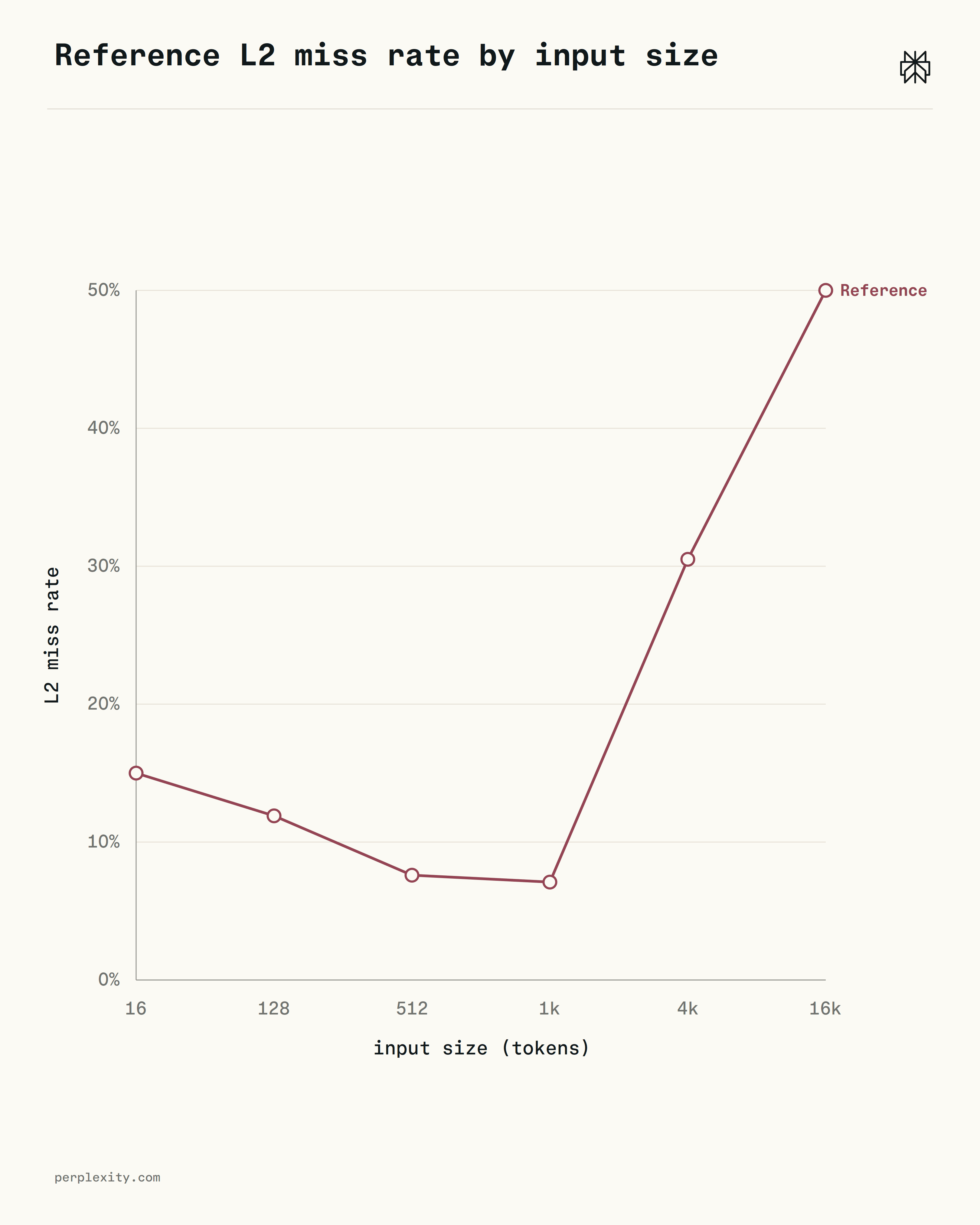
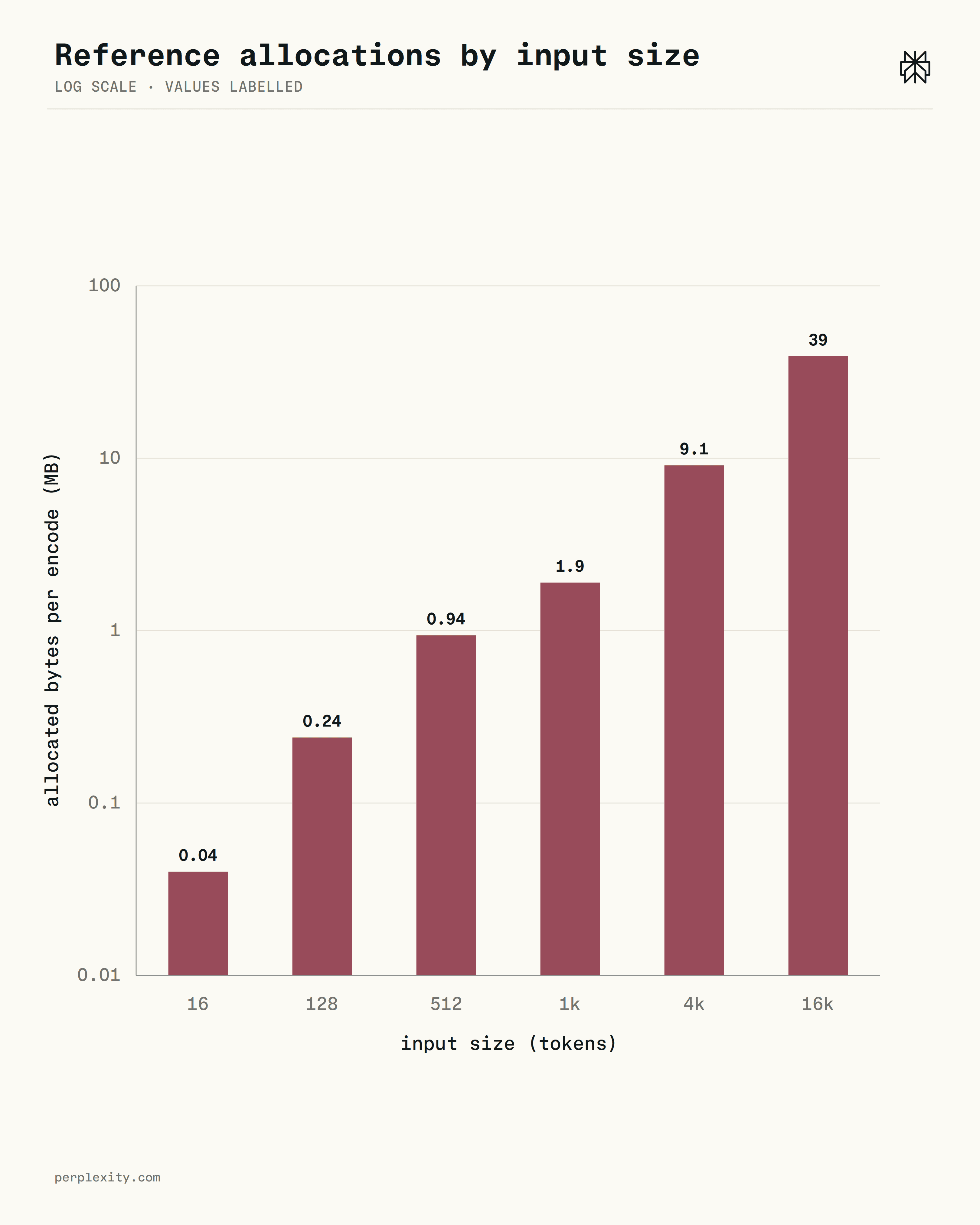
Per-token allocation is constant: about 2 KB and ~18 allocations per token, regardless of input size. The latency non-linearity comes from L2: cumulative bytes cross 2 MB around 1k tokens, miss rate climbs from 8% to ~50%, and the p99 curve bends to match.
How We Measured
We compare three production tokenizers, all running the same Unigram algorithm against the same XLM-RoBERTa model:
Engine | Language | Trie |
|---|---|---|
Hugging Face | Rust | HashMap-children prefix trie |
SentencePiece | C++ | Darts double-array trie |
IREE tokenizer | C | Darts double-array trie |
We link SentencePiece and IREE through direct C/C++ FFI rather than their Rust wrappers; the wrappers add per-call allocations and string conversions that are not part of the underlying library's cost.
All engines are built with full optimizations (O3, native targeting, link-time optimization). Measurements run pinned to one quiet core on an Intel Xeon Platinum 8488C. For each engine and input size we collect wall-clock latency (p50 and p99, 10,000 iterations after 1,000 warmup), instructions retired via Valgrind cachegrind, IPC and cache miss rates from perf stat hardware counters, and heap allocations counted by a global allocator wrapper around the measured window.
At 514 tokens (the +2 over 512 is BOS/EOS injection):
Implementation | p50 latency | Instructions | IPC | Allocations |
|---|---|---|---|---|
Hugging Face | 349 µs | 3.60M | 2.89 | 7,295 |
SentencePiece | 128 µs | 1.83M | 3.39 | 1,559 |
IREE | 112 µs | 2.28M | 3.06 | 1 |
SP and IREE land at roughly a third of the reference's latency. They retire about half as many instructions, run at higher IPC, and allocate one to two orders of magnitude less.
Why SentencePiece and IREE Are Faster: The Double-Array Trie
SentencePiece and IREE both use the double-array trie introduced by Aoe in 1989 (Aoe, 1989; Karoonboonyanan). The trie is encoded in two flat integer arrays, base and check:
A child lookup is:
Each step of the trie traversal needs only two array loads, one integer add, and one comparison, with no hashing, no pointer chasing, and no per-node heap allocation. The construction places each node so that its children fall on free slots in the validation array, letting multiple parents share regions as long as their children differ on the byte they follow.
For XLM-RoBERTa's 250K vocab, the whole trie fits in ~9 MB of contiguous memory (~780K slots × 12 bytes for the offset, validation, and token ID per slot). A single encode's hot working set is on the order of 100 KB, comfortably in L2, and the hardware prefetcher locks onto the regular access pattern.
The reference, by contrast, keeps a hash-map of children per node, costing roughly four dependent loads per byte step. Hash the byte, load the bucket, follow a pointer to the bucket entry, follow another pointer to the child node on the heap, then consult its own hash-map for the next byte. Heap objects scatter and most loads miss cache.
SP and IREE both store the token ID directly in the trie node. The reference trie implementation returns only the matched bytes, so the encoder has to allocate a fresh string for each match, look it up in a side hash-map to recover the token ID, and read the score from a separate vector. SP returns the ID as the trie's stored value and reads the score from a flat float array:
IREE uses a stateful cursor API instead of returning all matches in a single call, but the cost model is the same: token IDs and scores are reachable as flat-array indices, with no allocation or hashing on the trie walk itself. IREE allocates only one output buffer per encode; SP additionally allocates a lattice node per match during the DP, totaling roughly 1,559 allocations at 514 tokens.
Baseline: A Zero-Allocation Port of the Reference
Before changing the trie, we isolate algorithm cost from implementation cost: how fast does the reference run with the unnecessary work removed?
The baseline keeps the reference's hash-map-children trie but makes two changes. A caller-owned scratch struct holds the DP table, preprocessed bytes, and output token IDs, so the hot path makes no allocations after warmup. The token ID and score are stored directly in the trie node, removing the per-match string conversion and the side hash-map lookup.
Inner loop:
This is the same algorithm, with the same trie shape and same access pattern, just with no allocations and no redundant lookups. Results at 514 tokens:
Engine | p50 | Instructions | IPC | Allocations |
|---|---|---|---|---|
Hugging Face | 326 µs | 3.66M | 2.86 | 7,295 |
SentencePiece | 127 µs | 1.81M | 3.55 | 1,559 |
IREE | 111 µs | 1.58M | 3.26 | 1 |
Baseline | 156 µs | 1.53M | 2.62 | 0 |
Removing per-match string materialization and the secondary hash-map lookup cuts instructions 2.4× versus the reference. IPC drops with them (2.86 → 2.62) because the hash-map pointer chase, previously hidden behind allocator work, is now the dominant per-byte cost.
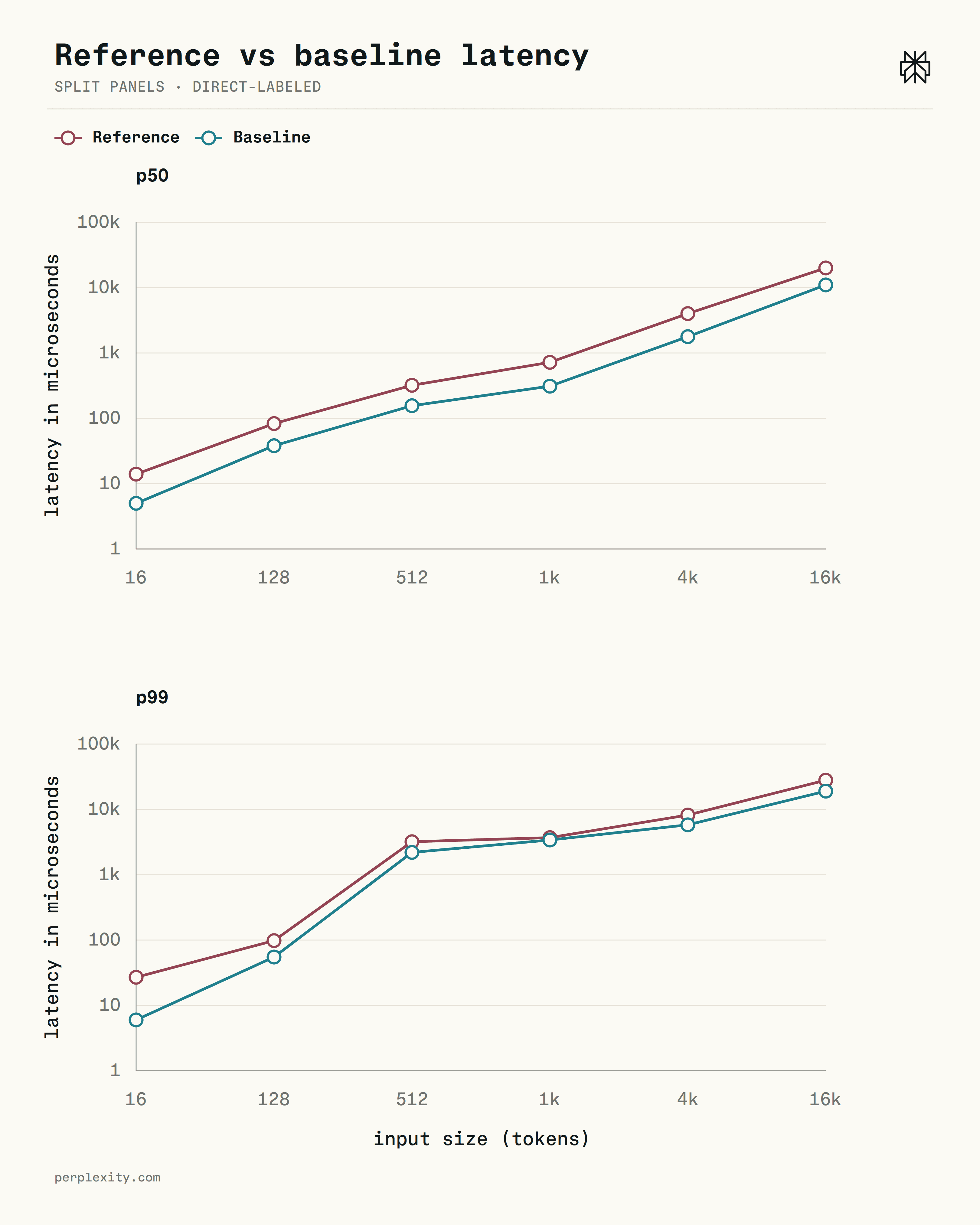
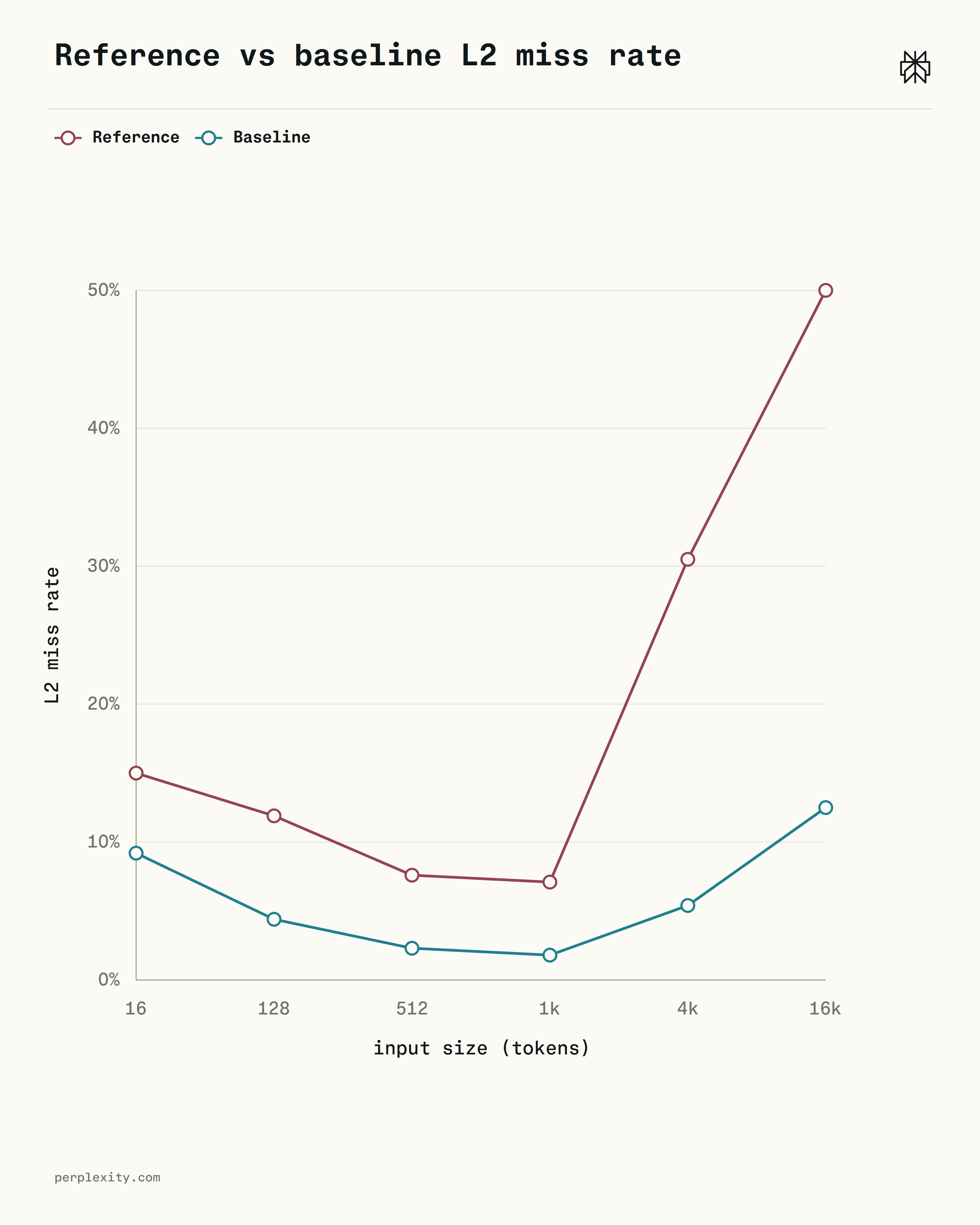
The baseline cuts p50 latency by 2-3× versus the reference at every size, and its L2 miss rate stays near 2-3% through 2k tokens versus the reference's 8-48%. The remaining cost is the HashMap pointer chase, which the next section addresses.
Optimization 1: Double-Array Trie Without Extra Abstractions
The hash-map trie is a pointer chase. SP and IREE solve this with a double-array trie (see the previous section), and we borrow the same data structure. The difference is that SP and IREE are general-purpose libraries supporting streaming input, output offsets, and multiple encoding modes; that flexibility costs them extra bookkeeping around the trie (a lattice in SP, an eight-stage pipeline in IREE). We do not need any of it, so we inline the trie directly in the Viterbi loop and drop the rest.
A byte step costs two array reads, an integer add, and a comparison. The whole trie is around 9 MB, but any single encode only walks ~100 KB of it, so the hot data stays in L2.
Engine | p50 | p99 | Instructions | L2 miss% | L3 miss% |
|---|---|---|---|---|---|
Hugging Face | 327 µs | 3,340 µs | 3.66M | 8.17% | 14.66% |
SentencePiece | 127 µs | 1,140 µs | 1.82M | 4.74% | 4.07% |
IREE | 111 µs | 132 µs | 1.61M | 5.82% | 3.87% |
Baseline | 155 µs | 1,170 µs | 1.53M | 2.59% | 16.66% |
+ Darts | 68 µs | 80 µs | 1.10M | 6.45% | 11.42% |
Wall-clock drops 2.3× from the baseline and 4.8× from the reference. Instructions drop another 28% from the baseline. Cutting the lattice and pipeline lets us retire 1.10M instructions per encode against SP's 1.82M and IREE's 1.61M at the same trie shape; the gap is the bookkeeping they keep for general-purpose APIs we do not need.
Optimization 2: Bitmap and Inline Packing
The Darts trie from Optimization 1 needs two dependent loads per byte step. First the parent's base offset, then the check entry at the candidate child slot to confirm the parent owns it. The check entry only validates ownership. The same question can be answered by a per-node bitmap that records which bytes have children. By the construction of the double-array trie, the bit for byte b in the parent's bitmap is set exactly when the candidate slot for that byte is owned by the parent. The bitmap and the check array carry the same information, so we can drop the check array from the runtime structure entirely.
The bitmap lookup compiles to a single bit test against one 64-bit word, which runs in roughly a cycle. The related POPCNT instruction, which counts all set bits in a register, is what other bitmap-indexed trie designs use to compute a child offset from the bitmap directly. We do not need it because the Darts construction already stores that offset in the node's base field.
While we are at it, we pack the four per-node fields (bitmap, base, token ID, and score) into one 64-byte cache line. A single node visit now pulls in everything: the score and token ID we need at terminal nodes, plus the bitmap and base for the next step. The check array is only used during construction and is dropped from the runtime layout. Hot-path indexing is unchecked because trie construction and loop structure already guarantee the bounds. The trade-off is space: at 64 bytes per node × ~780K slots the trie grows from ~9 MB to ~50 MB.
Results at 514 tokens:
Engine | p50 | p99 | Instructions | L2 accesses | L2 miss% | L3 miss% |
|---|---|---|---|---|---|---|
Hugging Face | 327 µs | 3,340 µs | 3.66M | 15.0K | 8.17% | 14.66% |
SentencePiece | 127 µs | 1,140 µs | 1.82M | 7.5K | 4.74% | 4.07% |
IREE | 111 µs | 132 µs | 1.61M | 4.7K | 5.82% | 3.87% |
Baseline | 155 µs | 1,170 µs | 1.53M | 6.1K | 2.59% | 16.66% |
+ Darts | 68 µs | 80 µs | 1.10M | 4.6K | 6.45% | 11.42% |
+ Bitmap and Inline Packing | 65 µs | 77 µs | 1.06M | 1.8K | 20.53% | 15.01% |
Wall-clock systematically drops another 4.5% at 514 tokens and grows with input length, reaching 6-7% at 4k and 16k. Dropping the check array turns the per-byte trie step from two cache-line loads into one, which is 2.5× fewer L2 accesses per encode (1.8K versus the 4.6K of plain Darts). The miss rate jumps from 6% to 20%, but most of that is the denominator: with less than half as many accesses, the misses we do have take a larger share.
Optimization 3: Huge Pages for the Trie
The trie data is roughly 50 MB (780,000 nodes at 64 bytes each). On a default Linux process, that memory is backed by 4 KB pages, so the full trie spans about 12,000 distinct virtual pages, far past what the CPU's first-level data Translation Lookaside Buffer can hold (Sapphire Rapids has 96 entries). Each Viterbi step touches a different node, and over a 512-token encode we burn roughly 9,000 cycles in page-table walks, about 3% of the per-encode budget.
The fix is to back the trie with 2 MB huge pages instead of 4 KB ones. The same 50 MB now spans 25 pages, fits in the Translation Lookaside Buffer entirely, and the page-table directories themselves stop competing with the trie for L2 cache.
Linux has two ways to back memory with 2 MB pages. The opportunistic one is transparent huge pages (THP): your program asks the kernel to upgrade a memory region from 4 KB to 2 MB pages, and a background kernel thread tries to do it when it has time and contiguous physical memory available. The other alternative is to allocate the trie directly from a pre-reserved huge-page pool that the kernel sets aside at boot:
The pool needs to exist on the host (vm.nr_hugepages set at boot). On our production instances, 10,561 huge pages are reserved; the trie consumes 24 of them. After the mmap, /proc/<pid>/smaps confirms the region: KernelPageSize: 2048 kB, Private_Hugetlb: 49152 kB.
The gain is 3–12% wall-clock across input sizes, consistent and proportional to working-set length:
Tokens | Without huge pages | With huge pages | Δ |
|---|---|---|---|
130 | 15.7 µs | 15.2 µs | −3.6% |
514 | 65.4 µs | 63.1 µs | −3.4% |
1,026 | 129.5 µs | 125.3 µs | −3.3% |
4,098 | 773 µs | 679 µs | −12.0% |
16,386 | 3,808 µs | 3,554 µs | −6.8% |
The biggest win is at 4k tokens, where the working set is large enough that page-table traffic was actively competing with trie data for L2 bandwidth. Beyond 4k the gain shrinks because L3 misses dominate and page-table walks become a smaller share of total time.
Final comparison
Pulling the three optimizations together, here is the final engine measured against every other RoBERTa tokenizer we tested. Alongside the native C++ SentencePiece and C IREE binaries, we also benchmarked the off-the-shelf Rust wrapper crates a production user would reach for, sentencepiece and iree-tokenizer. The sentencepiece crate measures 1.6-1.9× higher latency than the native C++ binary at every input size, with the overhead coming from the wrapper allocating a fresh list of token pieces, each holding its own copy of the piece text, on every encode. The iree-tokenizer crate sizes its internal buffer to each input, which avoids a constant per-encode allocation that the native IREE binary pays regardless of input size, and that matters most at short inputs where the allocation would otherwise dominate the actual tokenization work. At production input lengths the constant cost amortizes and the wrapper's own per-call overhead from copying tokens back into Rust pushes its latency above the native binary's.

The final engine runs the same Viterbi over the same 250,000-token vocabulary, allocates nothing on the hot path, and produces token-exact output against the reference. Each byte step is now a single 64-byte cache-line load, one bitmap test, and one integer add, down from a HashMap probe, an allocator call, and several special-case branches in the baseline implementation. Instructions per encode fell from 3.66M to 1.04M, a 3.5× drop. Wall-clock matches that ratio at short inputs and widens further at long inputs, where the reference's per-token allocations start to overflow L2 and L3.
Closing Thoughts
In practice this work reduced CPU utilization in the preprocessing layer of our inference stack by 5-6× and shaved double-digit milliseconds off reranker latency.
The bulk of the latency reduction came from lightweight changes that removed wasted work: dropping per-encode allocations, replacing the HashMap-children trie with a double-array, and stripping the generic-API overhead. Using the existing per-node bitmap as the validity check and backing the trie with 2 MB huge pages combined accounted for 10-20% on top of the larger switch to a double-array trie, depending on input size.
The off-the-shelf Rust wrapper crates around SentencePiece and IREE illustrate the same point in reverse. On top of native C and C++ tokenizers, the FFI boundary and per-call allocations the wrappers introduce are visible in the latency numbers. The Rust source for the final Viterbi encoder is available at github.com/perplexityai/pplx-garden.
References
Hugging Face tokenizers — https://github.com/huggingface/tokenizers
SentencePiece — https://github.com/google/sentencepiece
IREE tokenizer — https://github.com/iree-org/iree
Kudo, T. (2018). Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates. https://arxiv.org/abs/1804.10959
Viterbi, A. J. (1967). Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Transactions on Information Theory. https://en.wikipedia.org/wiki/Viterbi_algorithm
Aoe, J. (1989). An efficient digital search algorithm by using a double-array structure. IEEE Transactions on Software Engineering. https://ieeexplore.ieee.org/document/31365/
Karoonboonyanan, T. An Implementation of Double-Array Trie. https://linux.thai.net/~thep/datrie/datrie.html
POPCNT (x86) — https://www.felixcloutier.com/x86/popcnt
Huge pages — https://docs.kernel.org/admin-guide/mm/hugetlbpage.html