pplx-embed: State-of-the-Art Embedding Models for Web-Scale Retrieval
Today we are releasing pplx-embed-v1 and pplx-embed-context-v1, two state-of-the-art text embedding models built for real-world, web-scale retrieval.

Today we are releasing pplx-embed-v1 and pplx-embed-context-v1, two state-of-the-art text embedding models built for real-world, web-scale retrieval. pplx-embed-v1 is optimized for standard dense text retrieval, while pplx-embed-context-v1 embeds passages with respect to surrounding document-level context.
Both pplx-embed-v1 and pplx-embed-context-v1 are available at 0.6B and 4B parameter scales. The 0.6B models target lightweight, low-latency embedding generation, while the 4B models maximize retrieval quality. In our evaluations, the pplx-embed family leads a range of public benchmarks including MTEB(Multilingual, v2), BERGEN, ToolRet, and ConTEB. Moreover, pplx-embed-v1 delivers best-in-class results on our internal web-scale benchmarks: PPLXQuery2Query, PPLXQuery2Doc.
The models produce INT8 and binary embeddings, reducing storage requirements by 4x and 32x, respectively, compared to FP32. This compactness makes web-scale embedding storage and retrieval significantly more practical.
Model | Dimensions | Context | MRL | Quantization | Instruction | Pooling |
|---|---|---|---|---|---|---|
| 1024 | 32K | Yes | INT8/BINARY | No | Mean |
| 2560 | 32K | Yes | INT8/BINARY | No | Mean |
| 1024 | 32K | Yes | INT8/BINARY | No | Mean |
| 2560 | 32K | Yes | INT8/BINARY | No | Mean |
Check out our technical report, Hugging Face models, and API docs.
Motivation
Dense text embeddings map queries and documents into a shared semantic space where retrieval reduces to approximate nearest neighbor search. At Perplexity’s scale, embeddings are the first stage of our retrieval pipeline, determining which documents from billions of web pages get considered by downstream rankers and language models.
Most leading embedding models today are built on decoder-only LLMs with causal attention masking, where each token can only attend to preceding tokens. For retrieval, this is a fundamental limitation: understanding a passage often requires bidirectional context. We address this through diffusion-based continued pretraining, which converts a causal LLM into a bidirectional encoder. Full bidirectional attention enables mean pooling over all token representations and supports late chunking for contextual embeddings, where each chunk’s embedding is informed by the full document it appears in.
At web scale, storing embeddings in FP32 is prohibitively expensive. Rather than applying quantization as a post-hoc compression step, our models use quantization-aware training to produce INT8 embeddings natively, reducing storage by 4x with no performance compromise. Binary quantization reduces storage by 32x with minimal quality loss, particularly at the 4B scale.
Many modern embedding models require instruction prefixes prepended to every input. While this can yield small lifts on benchmarks, in practice it adds friction: mismatched instructions between indexing and query time silently degrade retrieval, and selecting the right prompt for each use case becomes yet another thing to get right. Our models require no instructions, making integration straightforward.
Training
pplx-embed-v1 and pplx-embed-context-v1 are trained through a multi-stage pipeline that progressively shapes text representations for retrieval.
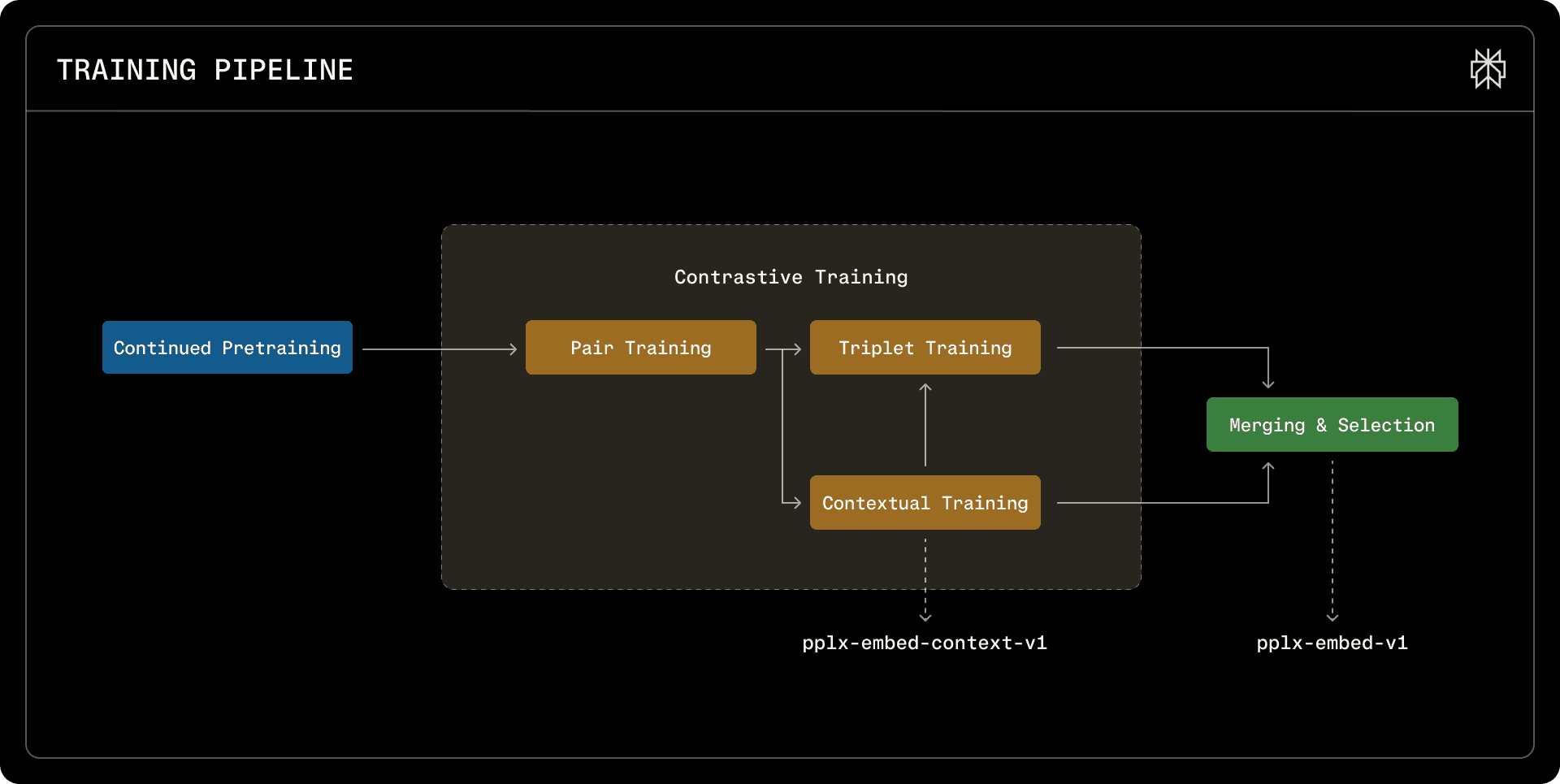
The multi-stage curriculum training pipeline. We combine four distinct training paradigms in a branched fashion, followed by a merging and selection stage.
Continued diffusion pretraining
We start from pretrained Qwen3 base models (0.6B and 4B) and convert them from causal decoders into bidirectional encoders by disabling the causal attention mask and training with a diffusion denoising objective. Unlike autoregressive models that predict tokens left-to-right, diffusion training forces the model to reconstruct randomly masked tokens using the full bidirectional context around each masked position. This means that by the time contrastive fine-tuning begins, the representations already encode bidirectional semantics, providing a stronger foundation for retrieval than a causal starting point. We pretrain on approximately 250 billion tokens of multilingual text spanning 30 languages. In ablations, diffusion-pretrained backbones achieve substantially lower contrastive training loss than their causal counterparts, translating to roughly a 1 percentage point improvement on retrieval tasks.
Contrastive training
Following pretraining, we perform three stages of contrastive learning. Pair training establishes foundational semantic alignment between queries and documents using an InfoNCE loss with in-batch negatives. With large batch sizes, some in-batch negatives are actually near-duplicates of the positive, so we apply a similarity-based mask to prevent these false negatives from corrupting the training signal. Training proceeds in phases—English-only, then cross-lingual, then fully multilingual—building capability gradually rather than all at once. Contextual training then teaches the model chunk-level semantics with respect to document-level context, using a dual loss that combines in-sequence and in-batch contrast at both the chunk and document levels—this stage produces pplx-embed-context-v1. Finally, triplet training with mined hard negatives refines the boundaries between similar but non-relevant documents. The final pplx-embed-v1 is obtained by merging the contextual and triplet checkpoints via spherical linear interpolation (SLERP).
Native quantization
Throughout all contrastive stages, embeddings are quantized to INT8 during both training and inference. We apply a tanh-based mean pooling operation followed by rounding, and use straight-through gradient estimation to backpropagate through the non-differentiable quantization step. This ensures the model learns representations optimized for reduced precision from the start, rather than suffering degradation from post-hoc compression. For binary quantization, the 4B models are notably more robust than 0.6B: their larger embedding dimension (2560 vs. 1024) preserves more information after binarization, limiting the performance drop to under 1.6 percentage points compared to 2–4 points at the smaller scale.
Public Benchmarks
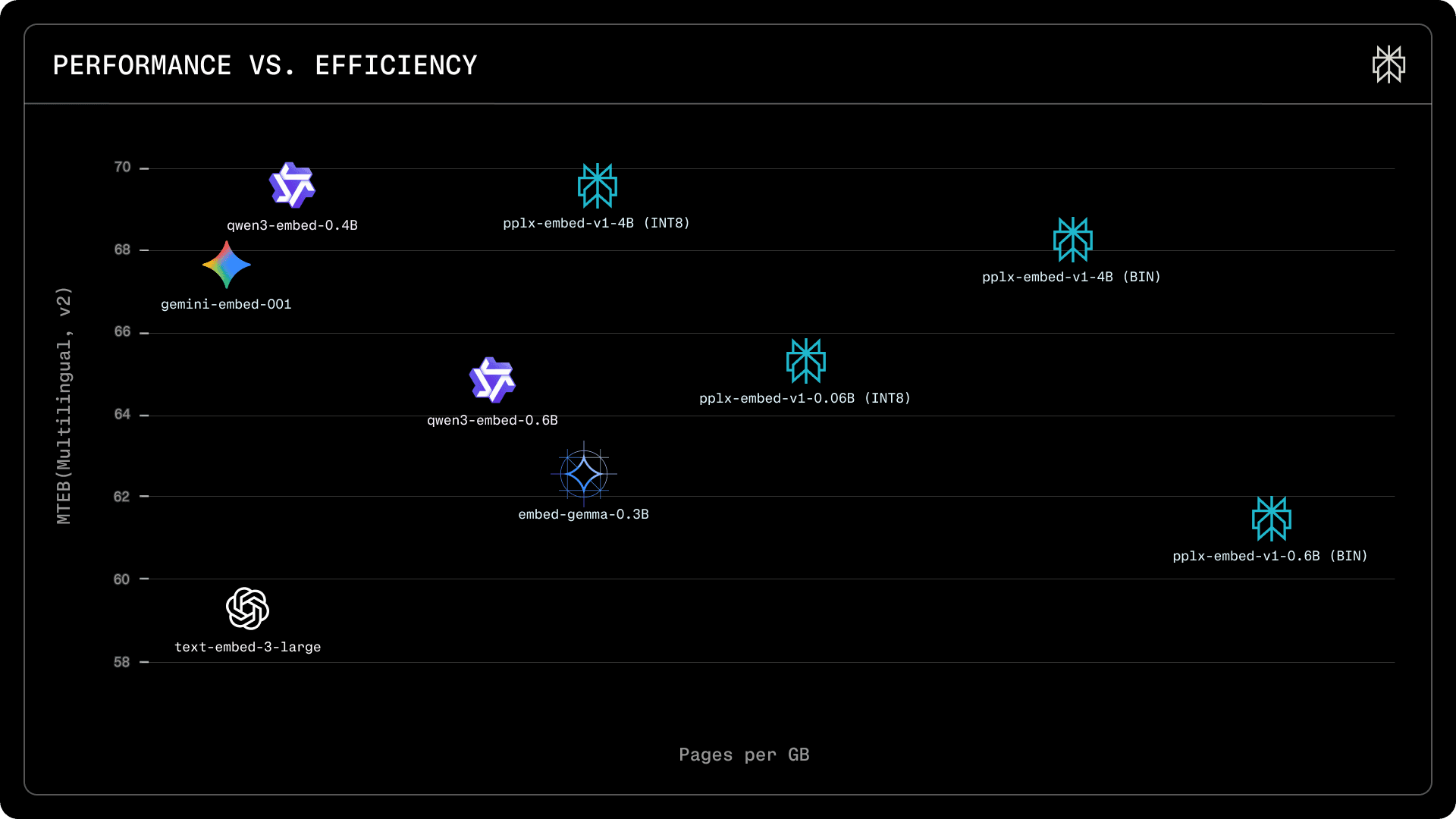
Retrieval performance on MTEB(Multilingual, v2). pplx-embed models shown with INT8 and BINARY precision variants. Our 4B INT8 model achieves competitive retrieval quality while storing 4 times more pages per GB than FP32 alternatives. The binary variant stores 32 times more pages per GB with only a 1.5-point performance drop.
On the MTEB(Multilingual, v2) retrieval benchmark, pplx-embed-v1-4B(INT8) achieves an average nDCG@10 of 69.66%, matching Qwen3-Embedding-4B (69.60%) and exceeding gemini-embedding-001 (67.71%), while requiring substantially less storage per embedding. Our 0.6B model outperforms its Qwen3 counterpart at the same parameter scale.
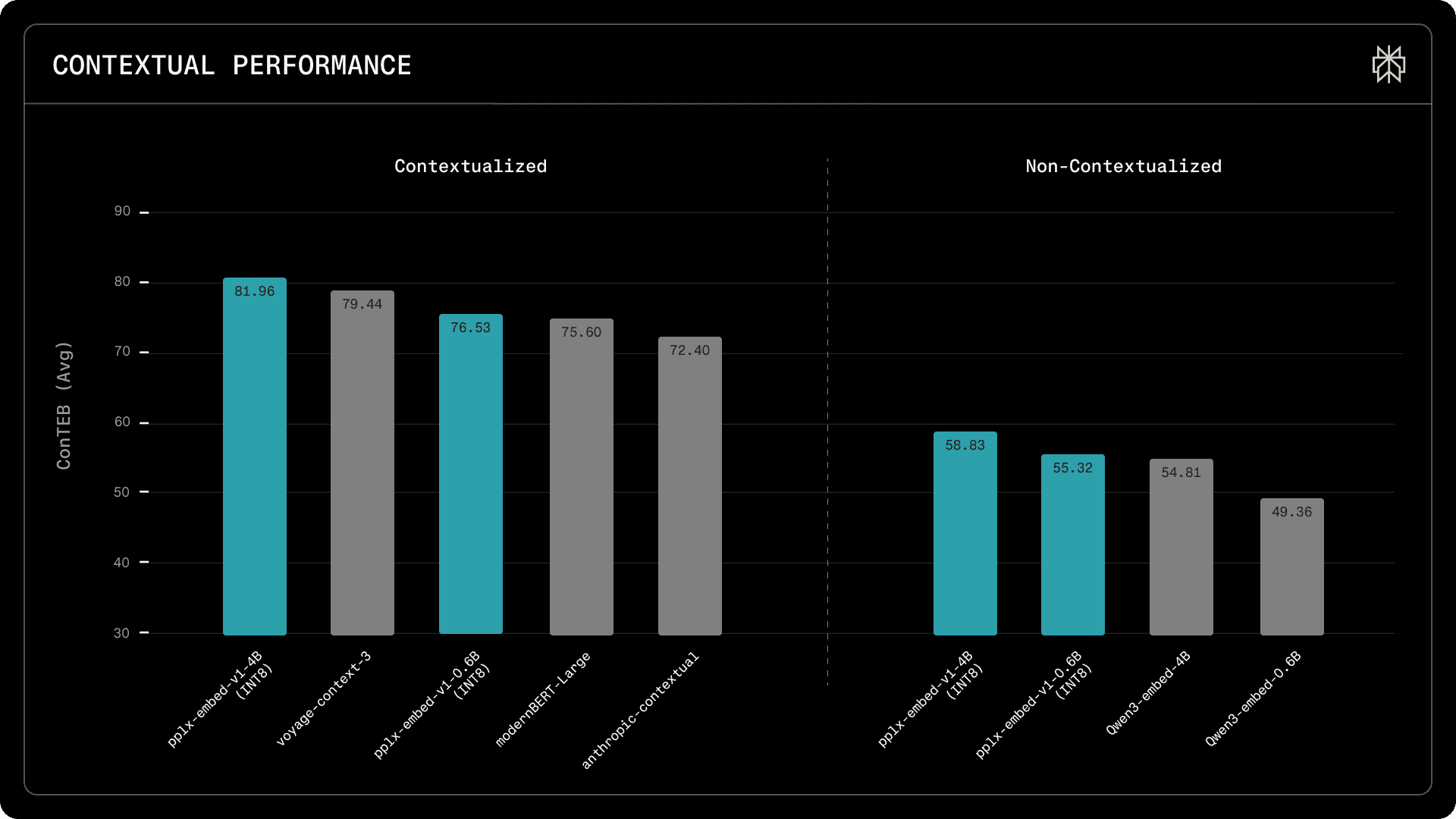
Contextual retrieval performance on ConTEB benchmark. Left: contextualized models. Right: non-contextualized models. pplx-embed-context-v1-4B (INT8) achieves the highest score of 81.96, followed by voyage-context-3 (79.45) and pplx-embed-context-v1-0.6B (INT8) at 76.53.
For contextual retrieval, pplx-embed-context-v1-4B sets a new state of the art on the ConTEB benchmark with an average nDCG@10 of 81.96%, outperforming voyage-context-3 (79.45%) and Anthropic Contextual (72.4%). By training chunk-level representations that incorporate document-level semantics, our models retrieve the right passage even when its meaning depends on surrounding context.
We also evaluate our models in end-to-end RAG using the BERGEN benchmark, where retrieved passages are fed to a language model to generate answers. pplx-embed-v1-4B outperforms Qwen3-Embedding-4B on four of the five evaluated question-answering tasks. Notably, pplx-embed-v1-0.6B outperforms the larger Qwen3-Embedding-4B on three of the five tasks, demonstrating that our smaller model can match or exceed a competitor at a significantly larger parameter scale in practical RAG settings. For more details on this evaluation, we refer to the technical report.
Real-World Retrieval at Scale
Public benchmarks are useful, but they don’t fully capture web-scale retrieval challenges: long-tail queries, noisy documents, and distribution shifts that characterize production environments. To measure what matters in practice, we built two internal benchmarks with up to 115K real-world queries evaluated against more than 30 million documents pooled from over 1 billion web pages. PPLXQuery2Query evaluates whether an embedding model can identify semantically equivalent queries from real search traffic; PPLXQuery2Doc measures document retrieval from a 30M-page corpus.
On PPLXQuery2Query (2.4M corpus), pplx-embed-v1-4B achieves 73.5% Recall@10, surpassing Qwen3-Embedding-4B (67.9%) by 5.6 percentage points. Our 0.6B model achieves 71.1% Recall@10, substantially outperforming BGE-M3 (61.8%) and Qwen3-Embedding-0.6B (55.1%).
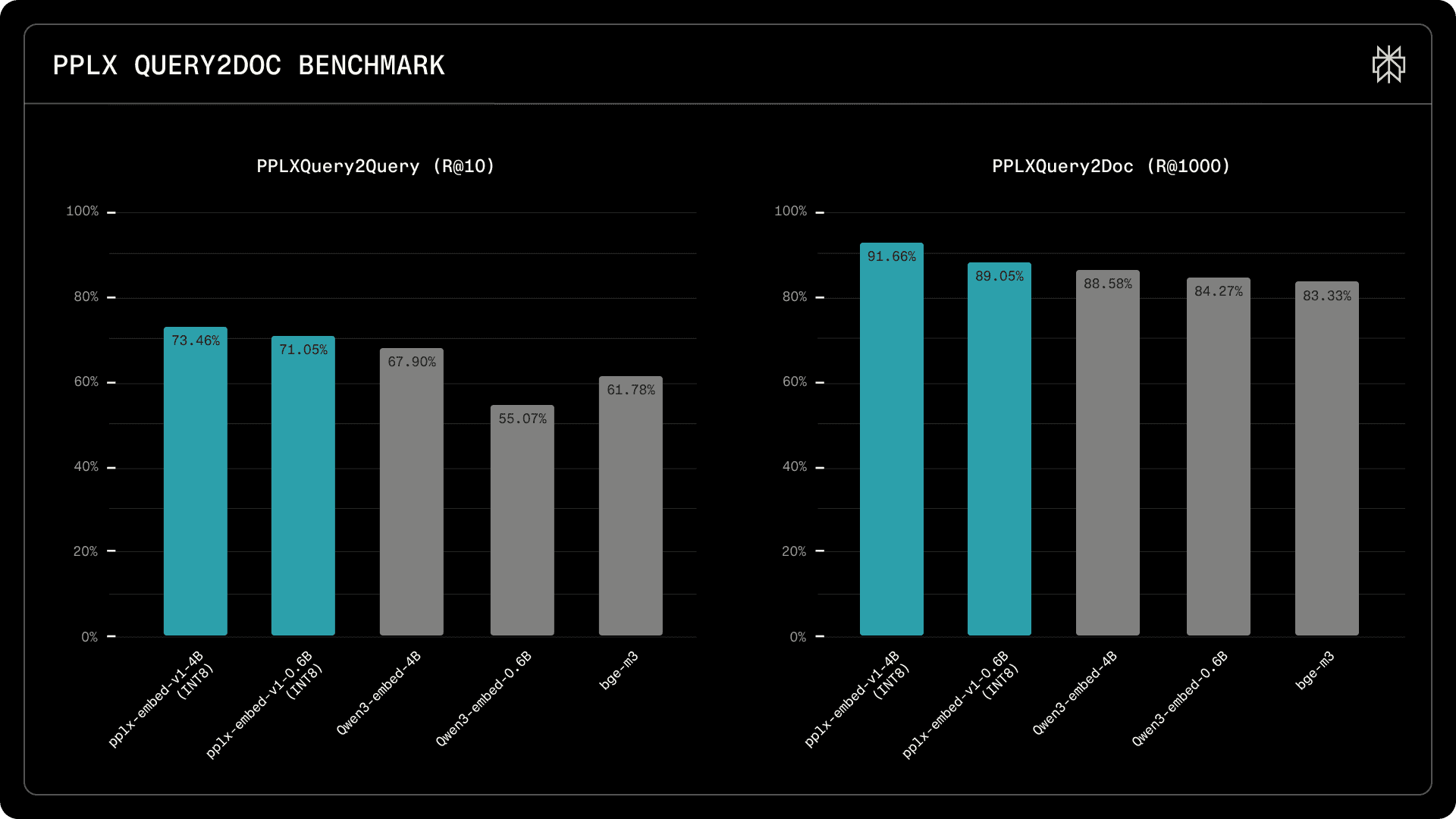
Multilingual PPLXQuery2Query (2.4M corpus) and PPLXQuery2Doc (30M corpus) retrieval benchmarks. pplx-embed-v1-4B (INT8) and pplx-embed-v1-0.6B (INT8) lead both benchmarks, demonstrating strong recall at scale for first-stage retrieval.
On the multilingual PPLXQuery2Doc task (30M corpus), pplx-embed-v1-4B achieves 91.7% Recall@1000, compared to 88.6% for Qwen3-Embedding-4B. High recall at large retrieval depths is critical for embedding models serving as first-stage retrievers in multi-stage ranking pipelines, where maximizing the number of relevant candidates passed to downstream rerankers directly impacts final result quality.
Getting Started
All models are available on Hugging Face (under MIT License) and through the Perplexity API. We support inference via Transformers, SentenceTransformers, Text Embeddings Inference, and ONNX. For full details on each option, see the Hugging Face model collection.
For comprehensive technical details and complete evaluation results, refer to our technical report.