Query-Aware Context Compression for Better Snippets
Improving the quality-efficiency frontier of model context through query-aware context compression models.

Every answer starts with evidence. In a search system, this evidence usually comes from documents: titles, summaries, chunks, and snippets that are passed as context to an answer model or agent.
This raw context is noisy. For instance, a web page may contain information needed for the user’s request, but it may also contain distractors. These distractors can appear both in the main body and in ancillary elements, such as nav text elements, irrelevant ads, metadata, and more. Passing these distractors to a downstream agent creates three problems.
First, it hurts accuracy. Even the most powerful models have finite capacity. Long streams of irrelevant information waste model capacity, resulting in “context rot” that impairs a model’s ability to address the actual user request. As a result, the final response is more likely to miss key facts, overweigh low-quality information, or produce claims that are harder to ground in the source.
Second, it regresses latency. Longer context means more tokens for the downstream model to process, especially when a query needs evidence from many candidate pages. Although part of this latency cost is borne at the prefill stage, a much more significant cost is paid in reasoning, with models requiring more reasoning tokens to deal with irrelevant context.
Third, it raises cost. Every unnecessary token passed to the model makes it costlier to serve the user’s request, as both input token and reasoning token usage increases with noisier context. Distractors don’t just reduce quality; they end up forcing you to pay more for that worse quality.
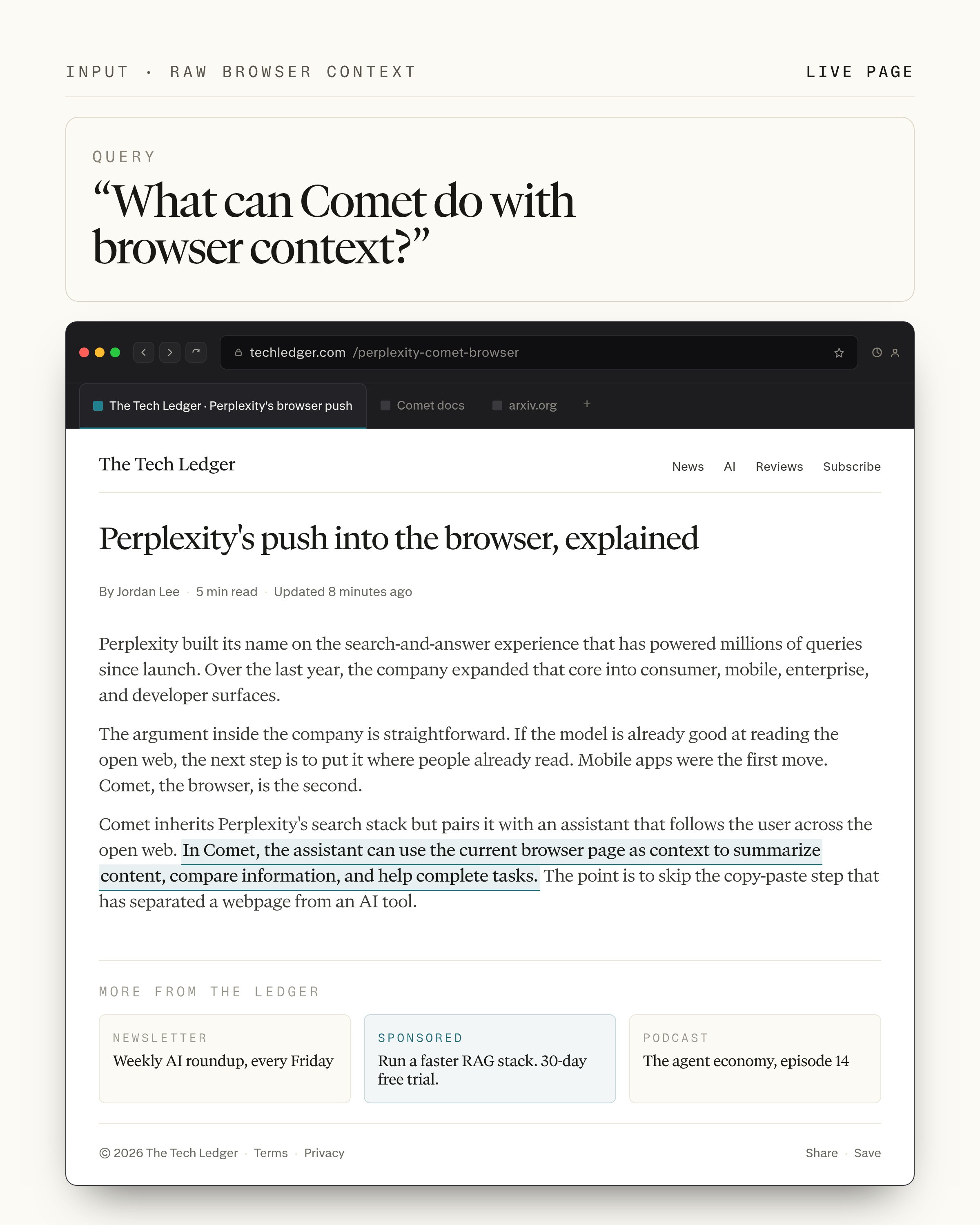
Figure 1. Raw retrieved context often contains the answer surrounded by irrelevant text. The useful evidence is present, but it is buried among headers, footers, boilerplate, metadata, and off-topic content before the answer model sees it.
To simultaneously advance accuracy, speed, and cost-effectiveness across Perplexity’s applications and API Platform, we invest heavily in improving context precision. One way we do so is through refining our snippet generation algorithms. We treat snippet generation as a context compression problem. Models looking for specific information do not benefit from generalized summaries or excerpts of a document. Rather, they need the smallest, most surgically extracted piece of source information to respond to the user’s request. Everything else can and must be removed.
A good snippet should therefore do three things:
Promote accuracy by presenting the precise evidence needed to ground the model’s response.
Reduce latency and cost by removing irrelevant context before the LLM call.
Ensure traceability by preserving citation fidelity and keeping source wording intact.
This month, we deployed a new, state-of-the-art snippet generator within our applications and API Platform. The core of this module is a query-aware context compression model which decides, for each query and candidate result, the subset of spans that should be preserved. This article describes our approach to building and training the model to achieve best-in-class performance on this critical task.
Snippets as Query-Aware Compression
The first order of business is to define the task itself. What do we want this model to do, and how should we define the input and output schema?
Snippet methods fall into two broad families. The first is selection-based: find a relevant window, chunk, sentence, or passage, and pass it downstream. The second is generation-based: ask a model to write a query-focused summary from the page.
Our focus on accuracy, latency, and cost makes the design choice clear. We can rule out generation, since creating a new summary for every page hurts performance across all three focuses. Summarization is a poor fit for the evidence layer we care about. It may paraphrase the source, making citation alignment harder. It can also introduce wording that was not present in the page, which is risky when the snippet is used as evidence rather than as the final answer. The latency and cost involved makes generation even more unpalatable.
Rather, we define our task as one of query-aware extractive compression: separating the helpful parts of the retrieved context from the distracting parts. Specifically, our model must accept a query and candidate result, and decide which spans to preserve, those that best support the query, and which to drop, the rest. The model output preserves source text rather than rewriting it. This makes the result easier to cite, easier to verify, and cheaper to pass downstream.
For example, consider this query and retrieved result:
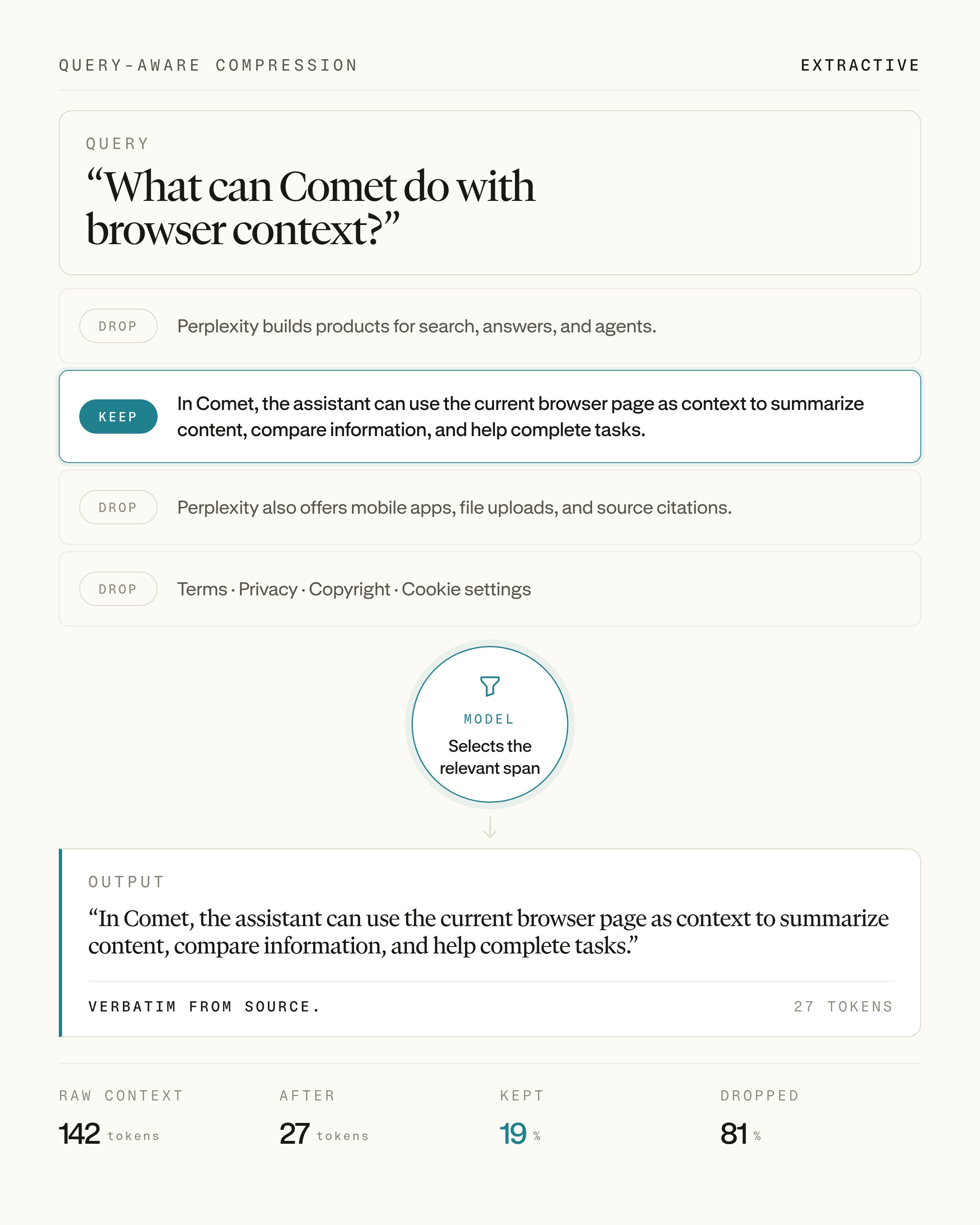
A plausible model output would be to select the bolded sentence: “In Comet, the assistant can ...”.
Our approach follows the same broad idea as prior context-compression work such as FliCo, Provence, and LooComp, adapted for snippet generation in a production search system. Importantly, the model works as a precision stage after our raw retrieval stage. As discussed in our previous Perplexity Research article, Introducing the Perplexity Search API, we architect our retrieval systems to operate natively at the sub-document, or snippet, level, which already allows us to balance precision and recall quite well. Introducing a query-aware context compression model shifts the precision-recall Pareto frontier even further outward.
Building and Training a Context Compression Model
We develop our model with three main considerations in mind: joint understanding of query and context, fine-grained sentence-level selection, and efficiency to fit within an extremely tight latency budget.
Model architecture
We use a pplx-diffusion model as a backbone. This is the same model family behind pplx-embed-v1, and both our prior academic work, Diffusion-Pretrained Dense and Contextual Embeddings, and our production benchmarks confirm it to be a strong bidirectional encoder for query-context pairs. One of the key properties from this model family is bidirectional context: each token representation can attend to the full query and the full candidate context before the model decides what should be kept.
On top of this backbone, we train a lightweight compression head that predicts which parts of the context should be kept. Because no generation is involved, these predictions are made in parallel across the entire context. At serving time, the snippet engine aggregates these predictions at the sentence level, applies a threshold, and trims the result to the requested token budget.
Supervision pipeline
Training this compressor requires supervision at the right level of granularity. A document-level relevance label is plainly unfit for our extractive compression task. To generate sufficiently granular data for supervised learning, we built a span labeling pipeline that marks query-relevant evidence spans, along with distractor spans that should be removed.
Our pipeline uses an LLM-as-a-judge setup. Given a user query and a candidate web page with its link, title, and summary, the judge first performs query understanding, analyzing the query and producing a list of possible user intents. Anchoring on these intents, the judge then processes the candidate context and returns spans copied verbatim from the text, with a category for each span to make the labels easier to inspect.
We then matched the returned spans back to the source text. Unsurprisingly, most judge outputs were already exact copies: naive string matching recovered 98% of spans. Adding a simple regex-based matching pass brought span recovery to 100%. This gave us reliable, granular spans that could be converted into token-level keep/drop supervision.
We evaluated this supervision pipeline using a small curated dataset with manually labeled spans, comparing smaller judge models, different prompts, and different step configurations. The best-performing setup was a two-stage pipeline: query understanding first, followed by categorized span labeling. We also validated the set of extracted spans through downstream verifiable evaluations such as BrowseComp and SimpleQA, where using only the kept evidence spans preserved strong scores while significantly reducing input tokens.
Using this pipeline, we labeled 750k query-document pairs and use the resulting spans to train the compression head with binary cross-entropy. This process allows our query-aware compression model to keep source text intact while removing context that is unlikely to help the downstream model serve the user’s request.
Ensuring realtime latency
Context compression sits before the downstream model, making it a blocking operation. Moreover, each compression is query-dependent. Therefore, the online path has to score query-context pairs for every candidate document within an exacting latency envelope. A slow compression model is self-defeating, as the latency benefits from higher precision are erased by the compression latency itself. At the same time, a less intelligent compression model will make poorer decisions on what to cut and retain.
The practical question is how much model capacity we can safely remove before compression quality starts to degrade. We compare the full 28-layer pplx-diffusion backbone against 11-layer and 17-layer variants produced by layer pruning and targeted at the search path. For each, we sweep over the compression threshold and measure two quantities: the average number of context tokens sent downstream per query, and the fraction of useful evidence preserved after compression.
Figure 2 shows the quality-efficiency frontier. A model is better when it moves toward the upper left: fewer downstream tokens with more useful evidence preserved. The 28-layer model provides the quality reference. The 11-layer model demonstrates the risks of compressing the model too aggressively. The pruned 17-layer model represents a middle ground: it closely tracks the 28-layer model in the saturated regime, but a small gap opens up in the steep portion of the curve where most production traffic operates.
To close that gap, we employ token-level knowledge distillation. Our approach is routine: we augment the standard loss with a soft cross-entropy term on the teacher model’s predictions, weighted by a distillation coefficient. This suffices to bring the student model to parity, allowing us to fully switch to the distilled 17-layer model in production. This new production model yields a 35-40% decrease in inference latency and 40-45% decrease in aggregate GPU compute with no quality drop relative to the 28-layer teacher. Production latency clocks in at under 20 ms (p99): small enough to add to the serving path while greatly reducing the total tokens passed to the answer model.
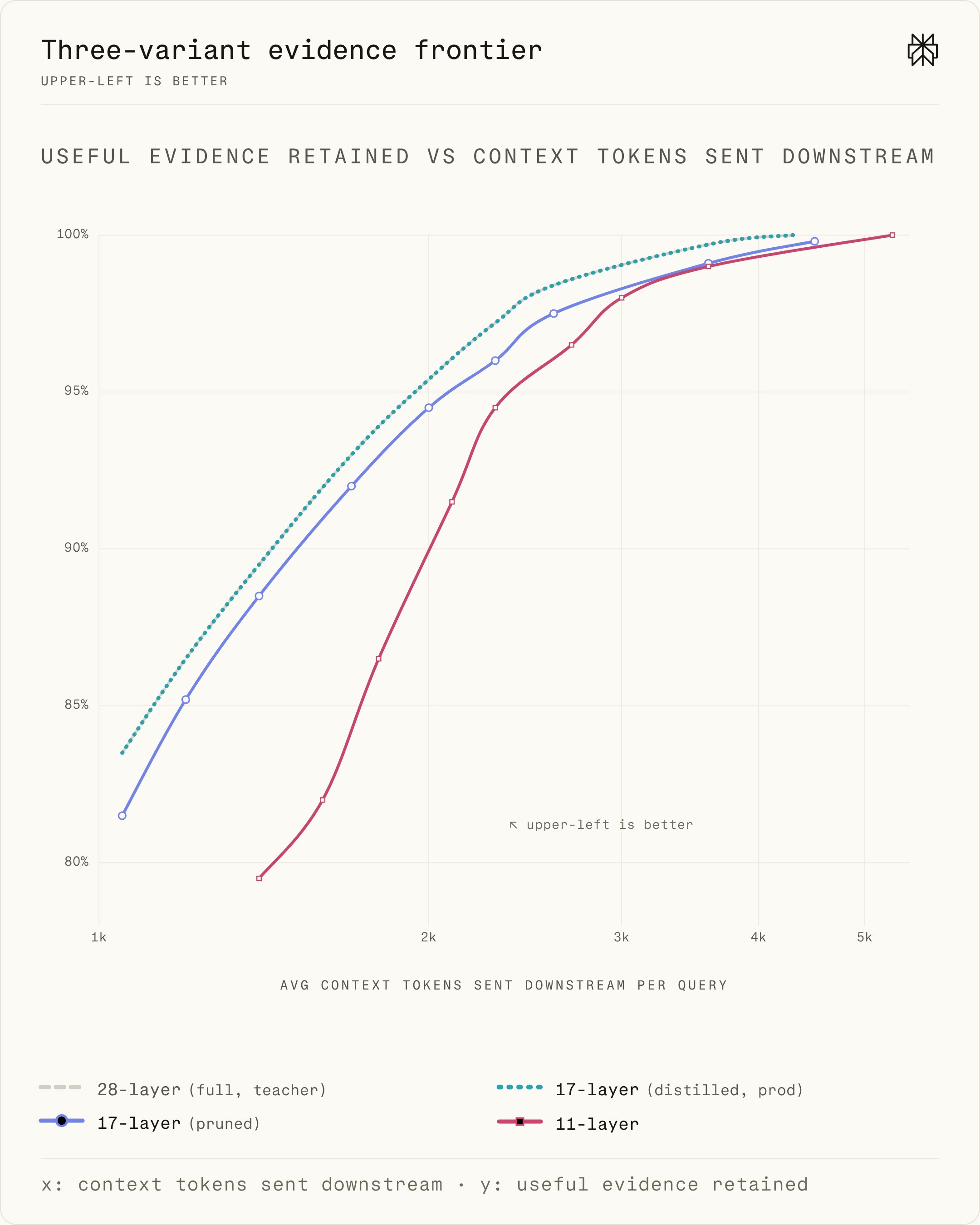
Figure 2. Compression performance across various model depths. The distilled 17-layer student, our production model, matches the 28-layer teacher in compression performance across all thresholds, at lower online compute cost.
Quality and Token Efficiency
We use Perplexity’s Agent API as a testbed to analyze the effectiveness of context compression. We evaluate three Agent API presets:
A “low” context preset that constrains the token budget for each result set to 1000 tokens.
A “medium” context preset that constrains the token budget for each result set to 4000 tokens.
A “high” context preset that constrains the token budget for each result set to 10000 tokens.
Both the standard, no-compression, and the compression settings are configured to respect these token budgets.
Agentic multi-step search (BrowseComp)
We first examine compression’s impact on agentic multi-step search workflows on the BrowseComp benchmark. We perform this evaluation using our open-source search_evals harness. Grading is identical across all runs, using OpenAI’s canonical BrowseComp LLM judge prompt.
The two dimensions of interest are benchmark accuracy and token usage. Importantly, we measure token usage at the query level rather than the individual step level in order to measure the actual token load incurred across the request lifecycle. Figure 3 shows the “score-token” frontier, accuracy score vs. token usage.
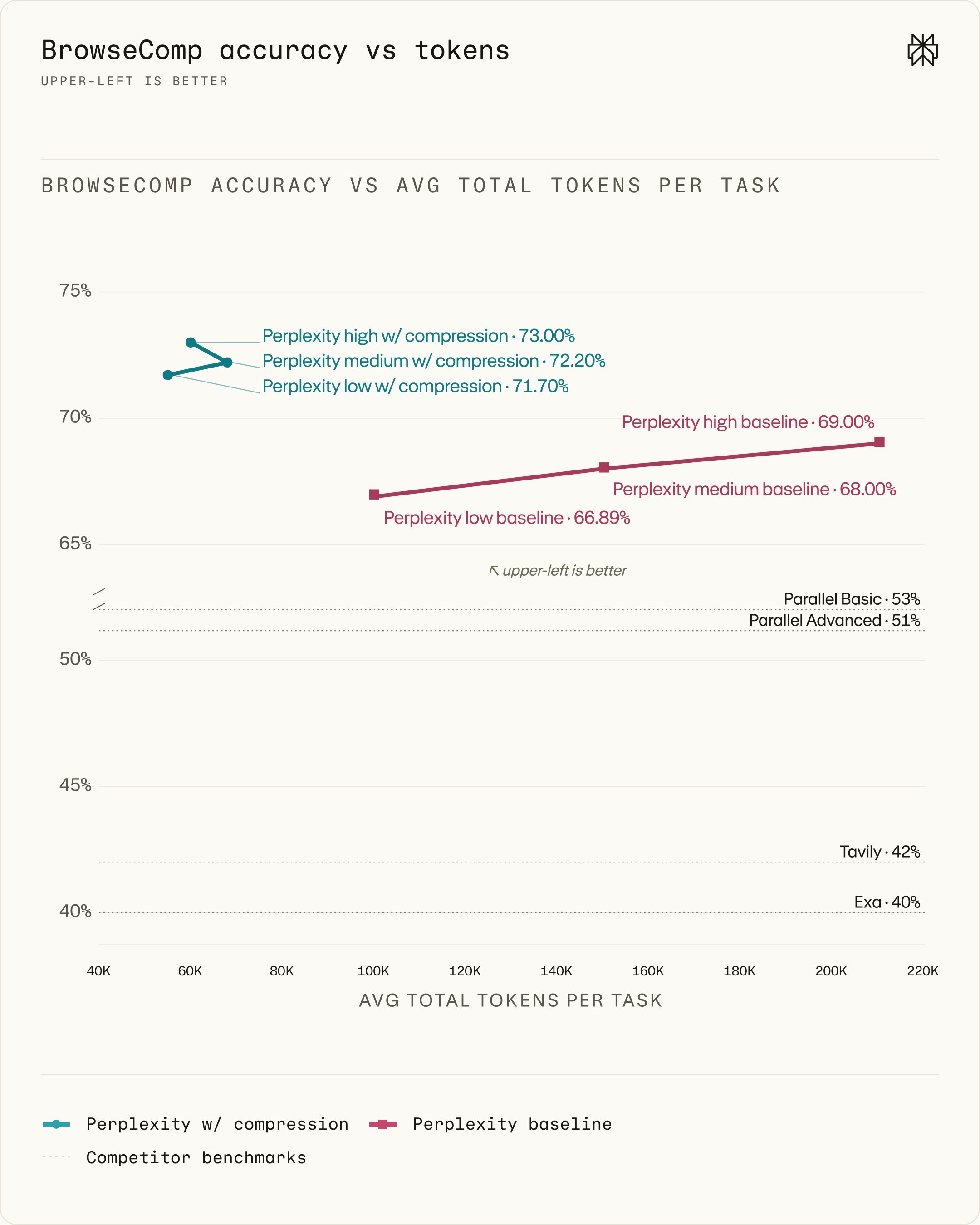
Figure 3. Score-token frontier on BrowseComp. Points on the top represent higher accuracy, while points on the left represent greater efficiency. Compression improves the Pareto frontier across all presets. Dotted horizontal lines represent non-Perplexity search systems, including Parallel benchmarks. GPT-5.5 powers the agent loop.
Compression delivers a new Pareto frontier across the board. For each setting, introducing compression reduces query-level token usage by anywhere from 10% to 70%, with accuracy gains clocking in between 4 and 4.81 percentage points. Introducing compression allows even our “low” preset to outperform the no-compression “high” preset, all while reducing token usage by more than three-fold.
We observe that with compression, “high” yields greater accuracy than “medium” as we might expect. Interestingly, however, it does so at lower token usage. This reveals a subtle but important effect of compression: with compression, even increasing per-step context size may enable the model to take fewer steps to arrive at the correct result. Exploring this non-monotonicity is a promising direction for future work.
SimpleQA: single-step factuality
BrowseComp stresses multi-step research, yet many production workflows involve single-step factual lookup. To determine whether compression also helps in the single-step regime, we also examine performance on SimpleQA, a benchmark comprising 4,326 questions to be answered in a single search step, rather than an agentic loop.
As before, we plot accuracy against average total tokens per task using the canonical judge prompt. Figure 4 shows the score-token frontier in this single-step setting. Although effect sizes are more compressed in the single-step setting, we again observe that compression simultaneously improves accuracy and efficiency across all presets, thus introducing a new Pareto frontier. With compression enabled, the medium preset achieves 95% accuracy with an average of only 200 tokens per document. Given the average document length of over 10,000 tokens, this represents frontier-level performance at a compression ratio of more than 50.
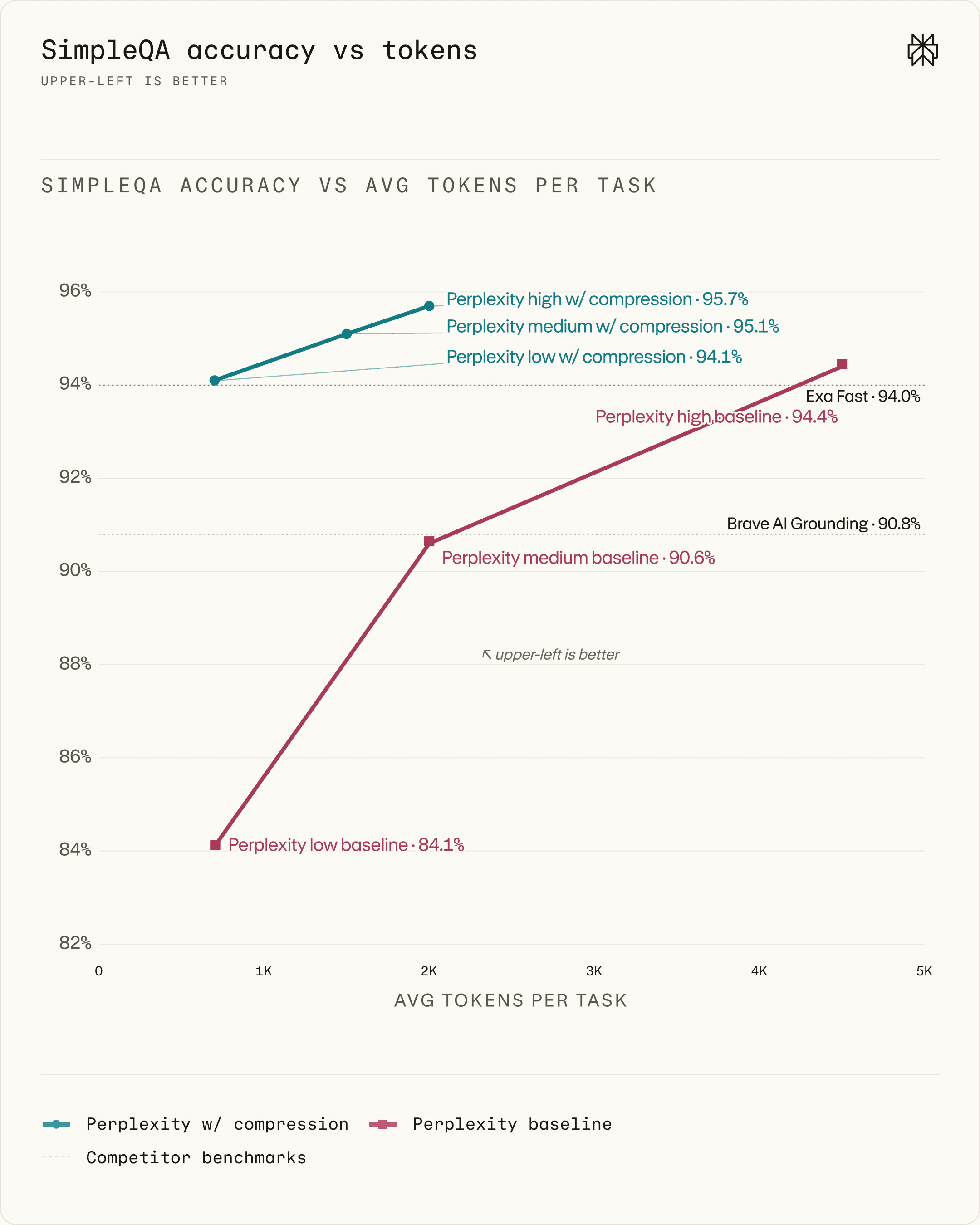
Figure 4. Score-token frontier on SimpleQA. Points on the top represent higher accuracy, while points on the left represent greater efficiency. Compression improves the Pareto frontier across all presets. Dotted horizontal lines represent non-Perplexity search systems, including Exa API evals.
What ends up in the snippets?
The downstream gains in Sections 4.1 and 4.2 are end-to-end. To understand how compression changes individual snippets, we run a separate evaluation that uses an LLM judge to classify every token of every retrieved snippet into one of six categories:
Vital: evidence essential to answer the user’s query.
Off-topic: information that may be useful for some other purpose but does not relate to the query at hand.
Ads: irrelevant advertising that distracts from answering the user’s query.
Metadata: metadata about the document’s contents.
UI & navigation: elements for frontend display and navigation.
Duplicate: repetition of previously incorporated information.
Our evaluation runs on 1,000 mixed-domain queries from our validation set, comparing the production stack against an otherwise-identical baseline with compression disabled. As shown in Figure 5, compression increases the proportion of vital tokens per snippet by an average of 63% over the no-compression baseline. We observe a corresponding decrease of 29% in irrelevant tokens, with particularly steep drops in UI/navigation (-58%), metadata (-46%), and ads (-43%). These results confirm the mechanism for the quality-efficiency improvements discussed above: compression improves performance across both dimensions by sharply increasing the signal-to-noise ratio of each individual snippet.
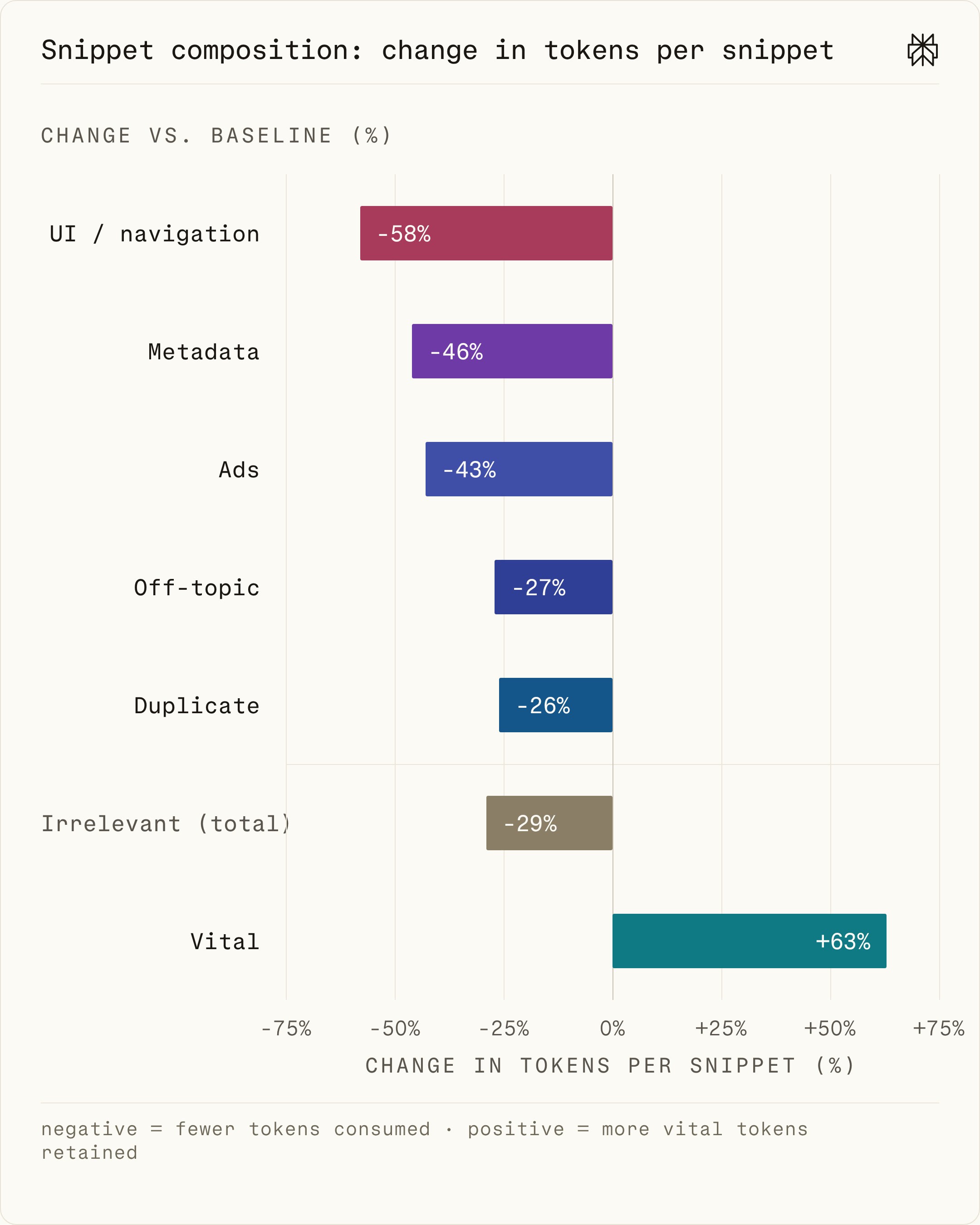
Figure 5. Change in per-snippet token composition from compression, averaged across 1,000 queries. The proportion of vital content increases, with corresponding decreases in non-vital content categories.
Figure 6 illustrates this change for an individual query. For the query “6 day old newborn milk intake per feeding,” we show both the uncompressed, baseline, and compressed snippets. Compression eliminates the non-vital content categories and retains only the newborn-related feeding information. Importantly, compression successfully eliminates content that might be generally on-topic for the page, but off-topic for this specific newborn-focused query.
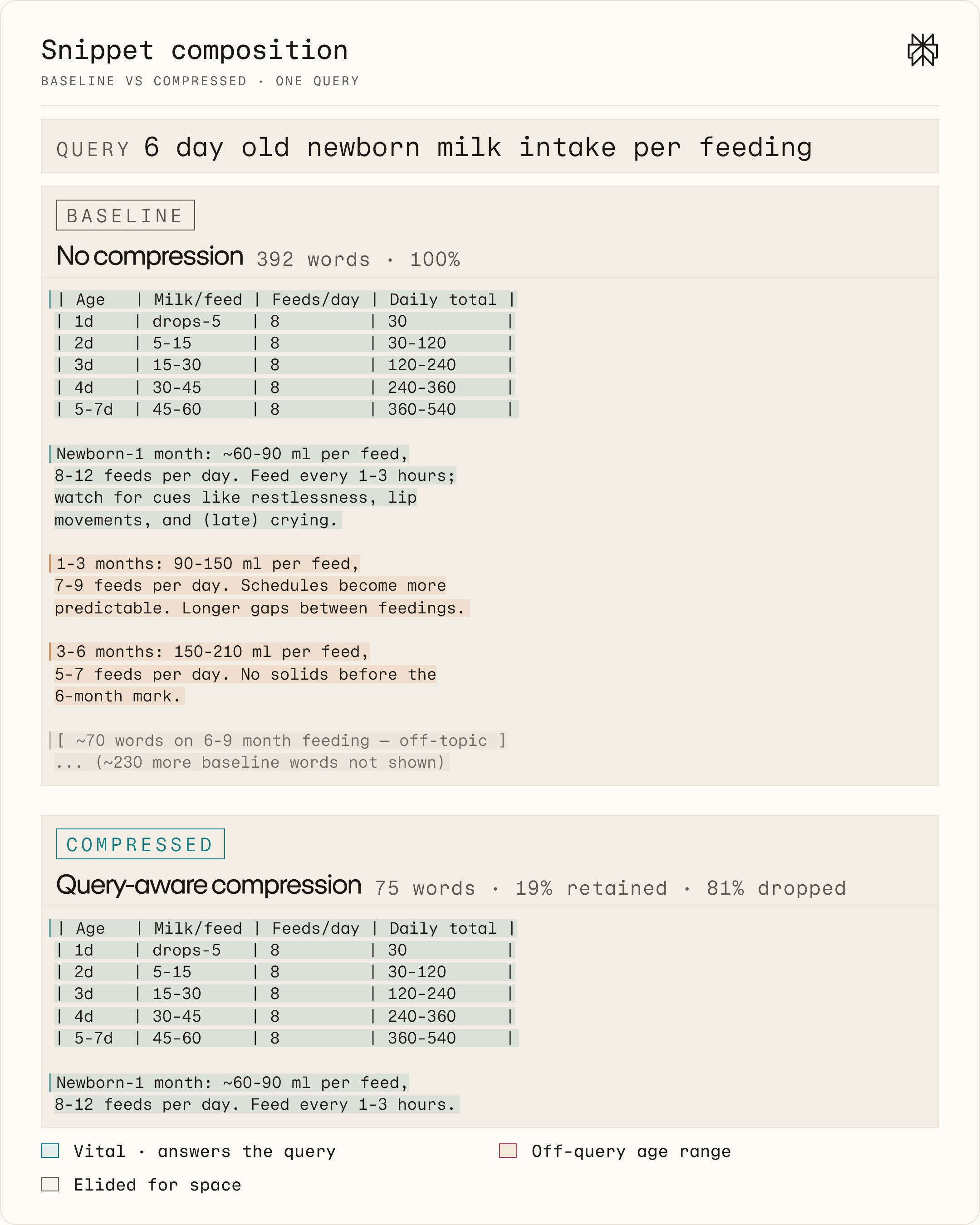
Figure 6. Snippets emitted by the no-compression baseline, top, and the compressed stack, bottom, for an example query-document pair. Compression retains only the first 19% of the baseline snippet, dropping the remaining 81% as irrelevant.
Conclusion
AI systems rely on high-signal information to intelligently and efficiently serve user requests. This information must be presented as surgically as possible to maximize relevance to each request. Our new query-aware compression models do precisely this by maximizing on-topic evidence per snippet and aggressively culling irrelevant distractors.
By deploying these new models within our search stack, we are able to provide faster and better responses to those who rely on our products and APIs. Our approach creates a simple control surface, allowing our systems and API customers to tune the degree of compression to balance between recall, latency, and cost.
Context curation is a developing field, and there’s much more to be done to optimize the value of each token used within today’s frontier intelligence systems. We are actively working to make our context curation techniques even better through both model improvements and system architecture to make even more expansive use of these models.
References
N. Chirkova, T. Formal, V. Nikoulina, and S. Clinchant. Provence: Efficient and Robust Context Pruning for Retrieval-Augmented Generation, 2025. Accepted to ICLR 2025. arXiv:2501.16214.
T. Do, D. P. Tran, A. Vo, S. K. Kim, and D. Kim. LooComp: Leverage Leave-One-Out Strategy to Encoder-only Transformer for Efficient Query-Aware Context Compression, 2026. arXiv:2603.09222.
S. Eslami, M. Gaiduk, M. Krimmel, L. Milliken, B. Wang, and D. Bykov. Diffusion-Pretrained Dense and Contextual Embeddings, 2026. arXiv:2602.11151.
Z. Wang, J. Araki, Z. Jiang, M. R. Parvez, and G. Neubig. Learning to Filter Context for Retrieval-Augmented Generation, 2023. arXiv:2311.08377.