systems
RDMA Point-to-Point Communication for LLM Systems
Elegant tool to address emerging LLM communication patterns

LLM systems have traditionally relied on collective communications for structured parallel patterns in training and inference. However, emerging workloads, such as disaggregated inference, Mixture-of-Experts (MoE) routing, and asynchronous reinforcement learning fine-tuning, demand the flexibility of point-to-point communication.
Our latest research paper introduces TransferEngine, a portable RDMA-based communication library that works across different Network Interface Controllers (NICs), including NVIDIA ConnectX-7 and AWS Elastic Fabric Adapter (EFA). We demonstrate its effectiveness in three production systems at Perplexity AI:
Disaggregated Prefill and Decode: Layer-by-layer KvCache transfer using paged writes and UVM watchers, allowing prefill and decode instances to scale independently.
Weight Transfer for RL Post-Training in under 2 seconds: Blazing fast weight synchronization between training and inference nodes.
Enabling Trillion-Parameter Models on AWS EFA: Low-latency MoE dispatch and combine operations using scatter and barrier primitives, achieving state-of-the-art latency on ConnectX-7 and the first viable implementation compatible with AWS EFA.
This article focuses on TransferEngine itself, the communication library that powers these systems. Read the full research paper on arXiv and explore the code on GitHub.
Motivation
Collective communications excel at structured parallel patterns such as Tensor Parallelism and Data Parallelism, but they impose constraints that limit their applicability to emerging workloads:
Fixed membership: Collectives require establishing a global communication world at initialization time, with synchronized setup across all participants. For disaggregated inference, this is problematic since the number of prefill and decode instances must scale dynamically in response to traffic patterns.
Uniform tensor shapes: Collectives assume all participants exchange tensors with identical shapes and data types. In MoE routing, the number of tokens sent to each expert is data-dependent and discovered at runtime, forcing dense all-to-all collectives to pad to worst-case buffer sizes.
Operation ordering: Collective APIs enforce synchronized semantics, even when applications only need to know that a set of operations has completed. For instance, in KvCache transfer, all pages from the prefill instance to the decode instance can arrive in any order. Similarly, in RL weight updates, all weight tensors can be transferred independently without ordering constraints.
RDMA-based point-to-point communication naturally addresses these limitations, but three barriers have prevented its adoption:
Library limitations: While torch.distributed and NCCL provide point-to-point APIs like Send/Recv, these operations still inherit collective semantics and limitations.
Hardware diversity: NVIDIA ConnectX NICs with Reliable Connection (RC) transport are the most common RDMA setup, guaranteeing in-order delivery. Cloud providers like AWS use different hardware, Elastic Fabric Adapter (EFA) with Scalable Reliable Datagram (SRD) transport delivers messages out-of-order. EFA also requires aggregating four 100 Gbps NICs (or two 200 Gbps NICs) to achieve 400 Gbps bandwidth.
Software portability: Existing RDMA libraries suffer from vendor lock-in. DeepEP requires GPU-initiated RDMA (IBGDA) available only on ConnectX. NVSHMEM exhibits severe performance degradation on EFA. Libraries like Mooncake and NIXL lack EFA support or remain in early development. As a result, no viable cross-provider solution exists for LLM inference.
TransferEngine
TransferEngine addresses these barriers through four core capabilities:
Common transport assumptions: Rather than targeting a specific NIC, TransferEngine assumes only that the underlying transport is reliable but unordered, i.e., the intersection of guarantees provided by both RC and SRD transports.
ImmCounter synchronization: A novel primitive for completion notification that works without relying on message ordering, enabling the same code to run on both ordered (RC) and unordered (SRD) transports.
Multi-NIC support: Transparent management of multiple NICs per GPU, automatically sharding transfers to maximize bandwidth.
Minimal API surface: A small set of operations sufficient to build complex communication patterns.
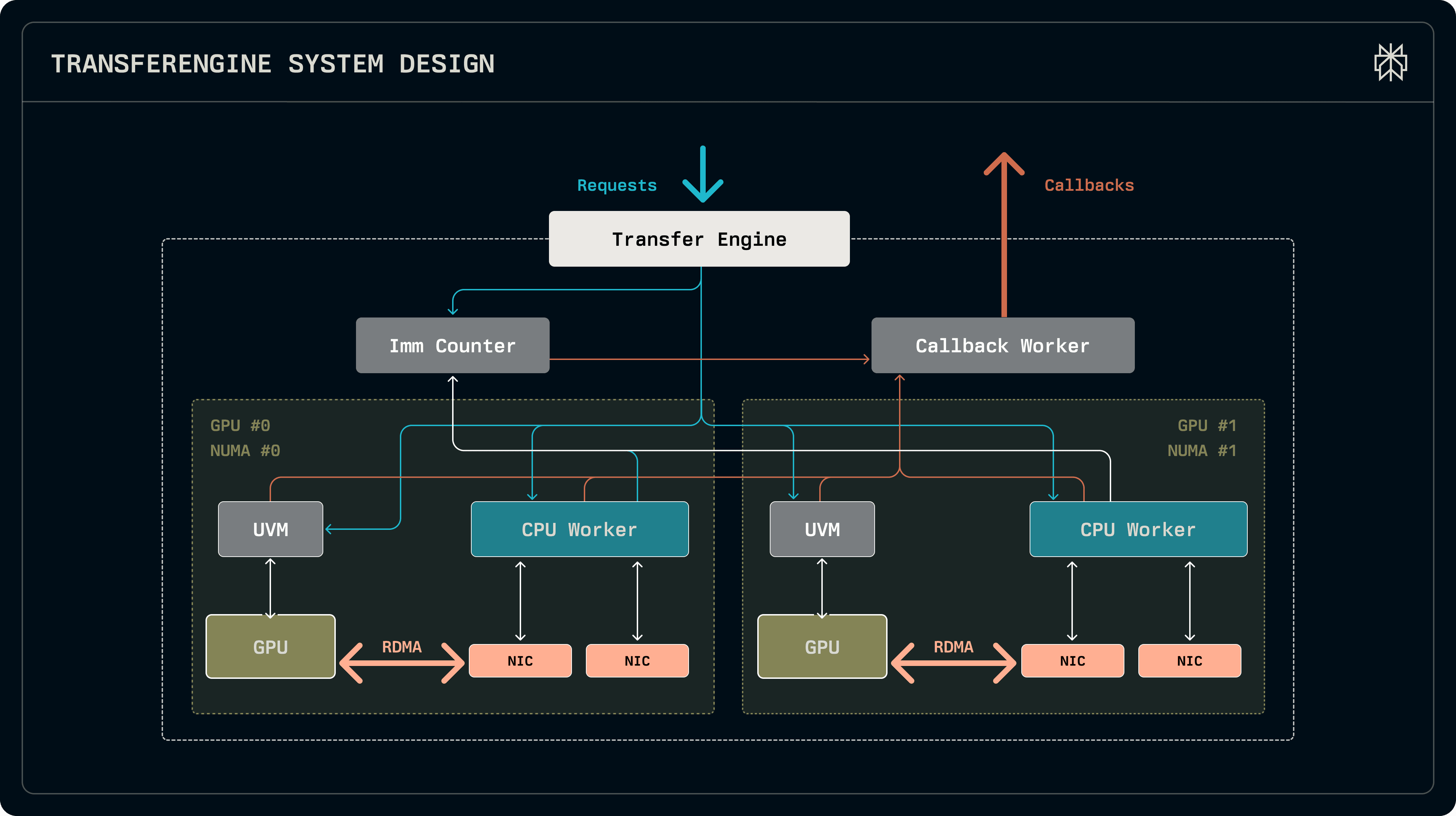
TransferEngine spawns one worker thread per GPU. Each worker manages a DomainGroup that coordinates 1 to 4 RDMA NICs, depending on the hardware platform (a single ConnectX-7 provides 400 Gbps, while EFA requires four 100 Gbps adapters or two 200 Gbps adapters). Within a DomainGroup, each Domain is hardware-specific and manages a single NIC, handling queue pair management, work submission, and completion polling.
Each TransferEngine instance exposes a single main address for peer identification and discovery. Remote peers exchange NetAddr structs that encode network addresses and can be serialized for out-of-band communication. All peers in a system must use the same number of NICs per GPU. This uniform configuration allows TransferEngine to shard transfers intelligently: when initiating a transfer, both source and destination know exactly which NICs are available, enabling automatic load balancing across all adapters.
API Design
TransferEngine exposes a minimal API that abstracts away the complexity of the underlying RDMA interfaces.
The API consists of several key components:
Memory Registration
RDMA operations require memory regions to be registered with the NIC before data transfer. The reg_mr function takes a pointer, length, and device, returning two handles:
MrHandle: A local handle used as the source for transfersMrDesc: A serializable descriptor that can be exchanged with remote peers to enable them to write to the registered memory
The MrDesc structure contains a list of remote network address and remote key (one per NIC) that grant remote access to the memory region. This design naturally handles multi-NIC setups.
Two-Sided Send/Recv
For small messages and RPC-style control plane messages, TransferEngine provides submit_send and submit_recvs:
submit_send: Sends the message to a remote peer identified byNetAddr. The message is copied internally, so the caller can immediately reuse or release the buffer.submit_recvs: Posts a pool of receive buffers. When a message arrives, a callback is invoked with the received data. The buffer is automatically returned to the pool after the callback completes.
One-Sided Write
For bulk data transfers, TransferEngine provides zero-copy one-sided write operations:
submit_single_write: Transfers a contiguous region from source to destinationsubmit_paged_writes: Transfers non-contiguous pages specified by indices, strides, and offsets
Both operations accept an optional 32-bit immediate value that is delivered to the receiver atomically upon completion.
The engine automatically shards large transfers across multiple NICs to maximize bandwidth.
Peer Groups and Bulk Operations
For operations targeting multiple peers (common in MoE routing), TransferEngine provides optimized primitives:
add_peer_group: Pre-registers a set of peer addresses for fast lookupsubmit_scatter: Sends different data slices to each peer in the groupsubmit_barrier: Sends an immediate-only notification to all peers (zero-byte transfer)
These operations are optimized for low latency by caching internal data structures and templating RDMA work requests, avoiding repetitive setup overhead.
UVM Watcher: GPU-to-CPU Signaling
A key challenge in LLM systems is coordinating RDMA transfers with GPU progress. Ideally, data transfer should begin as soon as the GPU produces output, but polling the GPU from the CPU is inefficient.
TransferEngine addresses this with UVM Watchers: unified virtual memory locations that can be updated by GPU kernels (even within CUDA graphs) and efficiently polled by the CPU using GDRCopy. When a UVM watcher is allocated, a callback is registered that gets invoked whenever the GPU updates the value.
This enables patterns like layer-by-layer KvCache transfer: after each transformer layer completes, the GPU increments the watcher, triggering a RDMA transfer of that layer's KvCache while subsequent layers continue computing.
Completion Notification
TransferEngine provides completion notification mechanisms for both the initiator side (the caller of submit_write) and the receiver side (the target of Write operations).
Initiator-side notification: When a write operation is submitted, the caller can choose to be notified upon completion through either a callback function or an atomic flag. This notification confirms that the data has been successfully transferred from the source buffer.
Receiver-side notification: The key innovation is the ImmCounter, a component that tracks counters indexed by 32-bit immediate numbers. When a write operation carries an immediate value, the receiver's ImmCounter is incremented atomically upon data delivery. The expect_imm_count function allows the receiver to register a callback that fires when a specific immediate value reaches a target count. The counters can be transparently synchronized with the GPU via GDRCopy, polled directly, or monitored through callbacks.
This receiver-side mechanism provides reliable synchronization without requiring message ordering. It works equally well on ConnectX NICs (which guarantee in-order delivery over RC transport) and EFA NICs (which deliver messages out-of-order over SRD transport).
Implementation
TransferEngine is implemented in Rust, carefully optimizing allocations, threading, and synchronization to minimize latency and achieve high throughput. The engine spawns one worker thread per DomainGroup, each pinned to a CPU core on the NUMA node to which the devices are attached, minimizing both scheduling and memory access latency. Data structures specific to a domain are allocated after pinning to ensure that memory is reserved in the correct NUMA node. One worker thread handles up to 4 Domains (each managing a single NIC), while another dedicated thread polls the GPU to update UVM watchers. Cross-thread communication is done through lock-free queues.
The API forwards requests to the DomainGroup serving the appropriate device, with the first one also serving the host. In a tight loop, the domain worker polls for new work, prioritizing the submission of new requests. Depending on the hardware and configuration, requests are sharded and load-balanced across the available Domains. The first Write of a composite request is immediately posted to the NIC's send queue. Once new requests are exhausted, the worker proceeds to progress pending operations, posting writes to fill up the hardware pipeline. Subsequently, completion queues are polled to query for finished transfers and immediate counter increments. Events are aggregated to deliver per-transfer notifications, handing the transfer over to a dedicated callback thread shared by all groups.
Sharding inside a DomainGroup is flexible. Transfers can target specific NICs by index. A single Write can be split. Paged transfers, scatter, and barrier operations, which all translate to multiple Writes, can shard across all NICs.
Hardware-Specific Optimizations
The Domains within TransferEngine are specialized and optimized for the hardware under their control:
AWS EFA: The EFA implementation uses libfabric, managing a fabric domain per NIC within the DomainGroup. Key implementation decisions and optimizations include:
Zero-sized writes: EFA diverges from the RDMA specification by requiring valid target descriptors even for zero-sized writes. Hence, TransferEngine enforces valid descriptors for all transfers.
Work request templating: Pre-populates and retains the common fields of
libfabricstructs before posting, reducing per-operation overhead for bulk transfers and peer group operations
NVIDIA ConnectX-7: The ConnectX-7 implementation uses libibverbs with RC transport. Key implementation decisions and optimizations include:
UD queue pairs for handshakes: Each
Domainuses a Unreliable Datagram (UD) queue pair to exchange RC connection handshakes.Separate RC queue pairs: Creates 2 RC queue pairs per peer, one for two-sided Send/Recv operations and another for one-sided Write and WriteImm operations. This separation is necessary because both Recv and WriteImm completions consume work requests in posting order, allowing high-level Recv semantics while supporting WriteImm without interference.
Work request templating: Pre-populates common fields of work request structures for bulk transfers and peer groups.
Work request chaining: Links up to 4 work requests through the
nextpointer ofibv_send_wr, reducing the number of doorbell rings to the NIC.Relaxed ordering: Enables
IBV_ACCESS_RELAXED_ORDERINGto permit out-of-order PCIe transactions between the NIC and GPU memory.
Conclusion
By targeting the intersection of guarantees across different RDMA transports and introducing order-independent synchronization via ImmCounter, TransferEngine provides a portable foundation for point-to-point communication in LLM systems. The library is open source and available on GitHub, and we encourage the community to explore and build upon it for emerging communication patterns in large-scale machine learning systems.