research
Hosting Qwen on Blackwell

NVIDIA GB200 NVL72 racks with NVIDIA Blackwell GPUs interconnected via 72-way NVLink are uniquely suited for deploying large mixture-of-experts (MoE) models. In this blog post, we describe the inference setup serving post-trained Qwen3 235B models that support a share of Perplexity’s traffic. We show how we adapted our in-house inference engine to leverage the advanced tensor cores and high-speed interconnect of NVIDIA Blackwell GPUs. With this hardware, we handle more traffic at a lower cost without sacrificing the accuracy of the underlying models.
Deploying on GB200 NVL72
GB200 NVL72 racks are composed of 18 nodes with 2 ARM-based NVIDIA Grace CPUs and 4 Blackwell-based GPUs, each equipped with 180GB of HBM. The 72 GPUs are interconnected via NVLink and 18 NVLink Switch ASICs, delivering 1800 GB/s of bandwidth between any two peers and sharing sufficient memory to host trillion-parameter models. Additionally, ConnectX-7 InfiniBand adapters deliver an additional 400 Gb/s of bandwidth both within the nodes of a rack and across neighbouring racks.
To handle traffic, we opted to post-train and serve Qwen models. In this blog post, we focus on Qwen3 235B, but many of the discussed serving techniques and performance characteristics are similar to those of the newer Qwen3.5 397B and 122B models that we are migrating to. In terms of parallelism, linear attention is similar to full self attention and the existing MoE layer implementation can be easily adapted to accommodate the new gate terms. To maintain a consistent decoding rate while maximizing throughput, we have chosen to disaggregate prefill from decode, deploying different parallelism strategies for the two kinds of nodes. Prefiller-to-decoder communication is handled over InfiniBand, whereas NVLink bandwidth is reserved for communication within prefillers and decoders. The performance characteristics of Blackwell devices when performing matrix multiplication and inter-device communication, explored in this blog post, determine the sharding strategies used. Compared to NVIDIA Hopper GPUs, we see kernel-by-kernel improvements due to the higher number of streaming multiprocessors, increased memory bandwidth and lower peer-to-peer latencies.
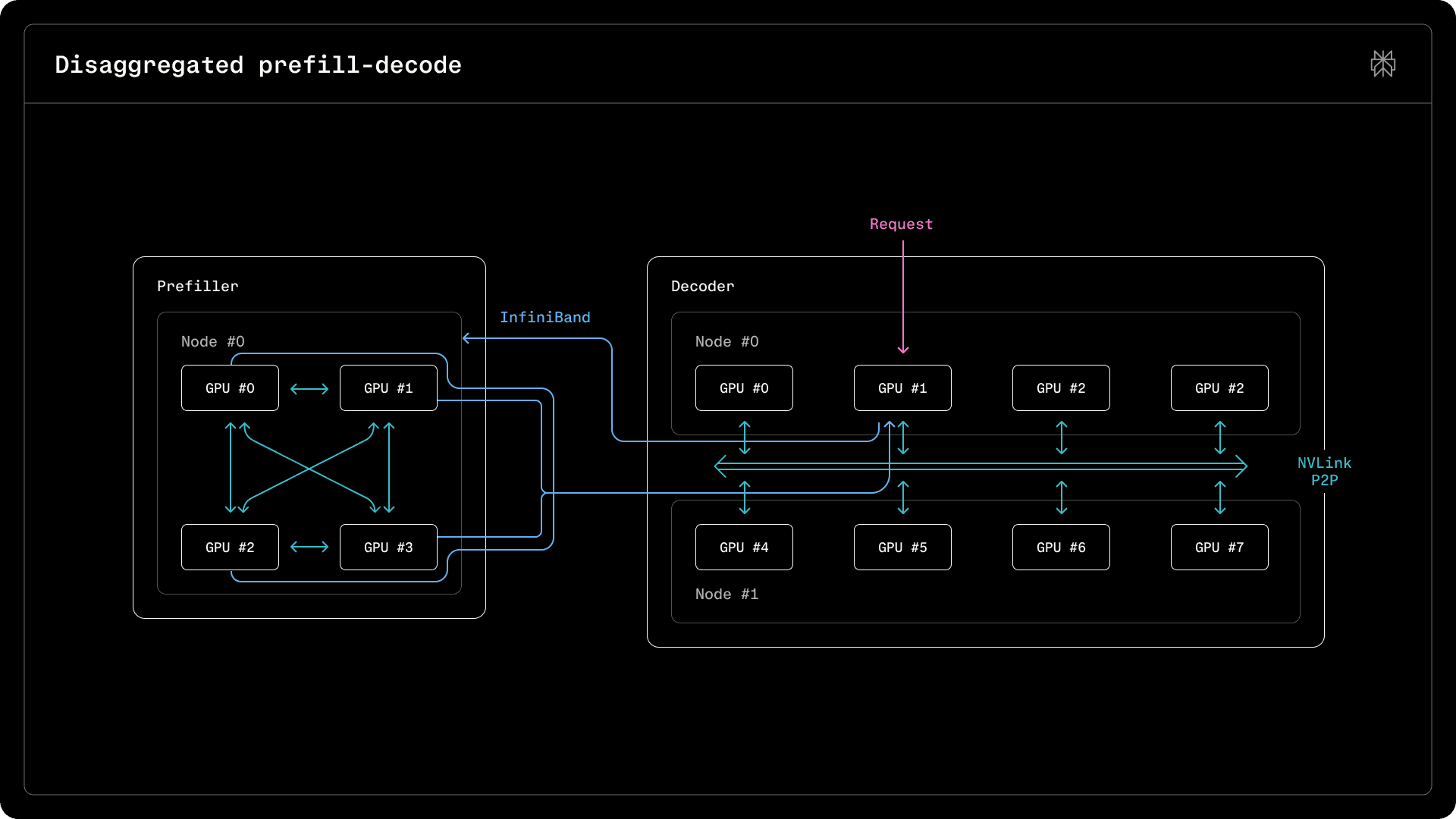
Our TransferEngine, which implements disaggregated prefill, handled arbitrary and possibly mismatched sharding across prefillers and decoders. The KV caches are laid out in memory in HND order, with heads in the leading dimension and tokens kept contiguous, to allow a sharded KV cache on a prefiller to be further split or concatenated in-flight during the transfer to the decoder node.
Prefillers
Prefiller nodes receive the input tokens of a request, populating KV caches and transferring them to the decoders to continue text generation. Prefill is computationally intensive, as thousands of tokens belonging to a sequence are processed at the same time.
Consequently, we found that a tensor parallel deployment is suitable, with the model sharded across 4 GPUs within a single GB200 node and projections and experts sharded (TP=4, EP=4). Since both attention and MLPs are compute-bound, both benefit from parallelism, distributing experts and attention heads across separate ranks. Further parallelism would have yielded diminishing returns, as the throughput improvement from hosting fewer experts on each rank (16 versus 32) would not have offset the additional cost of an 8-way all-reduce and the overhead of splitting the host-side code across two nodes, requiring communication over Ethernet.
Qwen3 235B has only 4 key-value heads, requiring the k and v projections to be replicated across pairs of ranks if 8 devices are used. We could have considered more aggressive sharding to reduce the amount of memory required to store weights on each rank, freeing up space for more tokens in the KV cache. However, we found that a wider deployment was not worthwhile.
Assuming an input length of around 6000 tokens, each of the 128 experts has around 6000 * 8 / 128 = 375 tokens routed to it, ensuring a dense problem for MoE GEMM. Since this already saturates the device’s computational throughput, data parallelism is not needed for prefill.
Despite the quadratically increasing cost of attention, prefillers deliver consistent throughput, allowing a rough estimate for the number of input tokens that can be processed by a node in a second. Relying on metrics tracking the total number of input tokens from requests, the number of prefiller nodes can be scaled up to ensure that the overall prefill throughput is sized accordingly. In order to avoid queuing, the number of prefiller replicas is matched to the total number of input tokens received.
Decoders
Decoder nodes receive the KV caches from the prefillers and generate tokens one-by-one. Decode is generally memory bound: with few input tokens, matrix multiplication is entirely bound by the cost of loading weights from HBM into Tensor Cores. Besides employing a different sharding strategy, several kernels have to be tweaked to better parallelize computations and memory accesses.
Unlike prefill, sharding attention is no longer beneficial: splitting attention heads across multiple devices would mean that there are fewer opportunities for parallelism within a single device. Consequently, only data parallelism and expert parallelism are used: experts are sharded across multiple devices, but each device manages its own KV caches and requests. Without tensor parallelism, the per-token KV cache size on a device is larger. However, space is freed up in memory by locating fewer experts on a single node. Unlike Hopper, where we limited tensor parallelism within a single NVLink domain in an 8-GPU node, on Blackwell we found that expanding across multiple nodes within a domain, using up to 16 devices, is beneficial.
In order to maximize throughput, decoders process a larger number of requests concurrently. Even though additional requests incur a minimal overhead in MoE layers and other projections, they do disproportionately increase the cost of attention. To maintain a reasonable minimum decoding speed, the number of decoder nodes is scaled to keep per-decoder batch sizes under a certain threshold.
Similarly to previous Hopper deployments, we use speculative decoding with MTP layers trained in-house to boost decoding rates. Fortunately, the underlying hardware and programming frameworks are similar enough to fully share the implementation between the two architectures.
Intra-node and Inter-node Communication
The main difference between GB200 NVL72 and previous Hopper nodes is the large NVLink domain, which enables peer-to-peer communication beyond the previous limit of 8 devices. Even though Blackwell devices have been deployed in 8-GPU nodes, there is a lot of value in scaling across multiple nodes over NVLink compared to the slower InfiniBand network.
On the prefiller nodes, we rely on all-reduce communication within attention layers and on an expert parallel reduction which closely resembles all-reduce. Across 4 GPUs, we leverage both NVLink and NVIDIA SHARP (Scalable Hierarchical Aggregation and Reduction Protocol): in addition to peer-to-peer bandwidth, we also exploit reductions in NVLink Switches to further reduce latencies and implement fast broadcasts. On decoder nodes, a custom all-to-all dispatch and combine implementation over NVLink is used. The kernels have been implemented in-house using CuTeDSL and cuMem mappings or multicast mappings.
All-Reduce
The prefillers perform an all-reduce operation in the output projection of the attention layer, summing up the contributions of the heads sharded across the participating ranks. Tensor parallelism is only effective when the cost of the all-reduce overhead is offset by the reduced latency of the smaller matrix multiplication problems. This assumption usually holds for prefill.
On datacenter-grade NVIDIA HGX H200 and GB200 NVL72 systems, GPUs are usually connected via NVLink Switches. Besides routing, the switches can perform reduction operations across connected devices via SHARP. After creating memory mappings and registering them into a multicast group using the CUDA APIs, kernels can use the multicast.ld_reduce and multicast.st to aggregate and broadcast values through the switches. In order to create a foundation and reusable components which can be fused into other kernels, we internally maintain a CuTeDSL all-reduce kernel using these primitives.
In a system with N GPUs reducing B bytes, a trivial implementation would have a peer load values from all other peers, for a total of N * (N - 1) * B bytes of read traffic. A more efficient implementation would split the data to be reduced across peers, with each reducing a slice of the input, then broadcasting it to the rest. This results in (N - 1) * (B / N) bytes read into a peer and broadcast to the rest, for a total of (N - 1) * B * 2 reads and writes, reducing traffic over the switches.
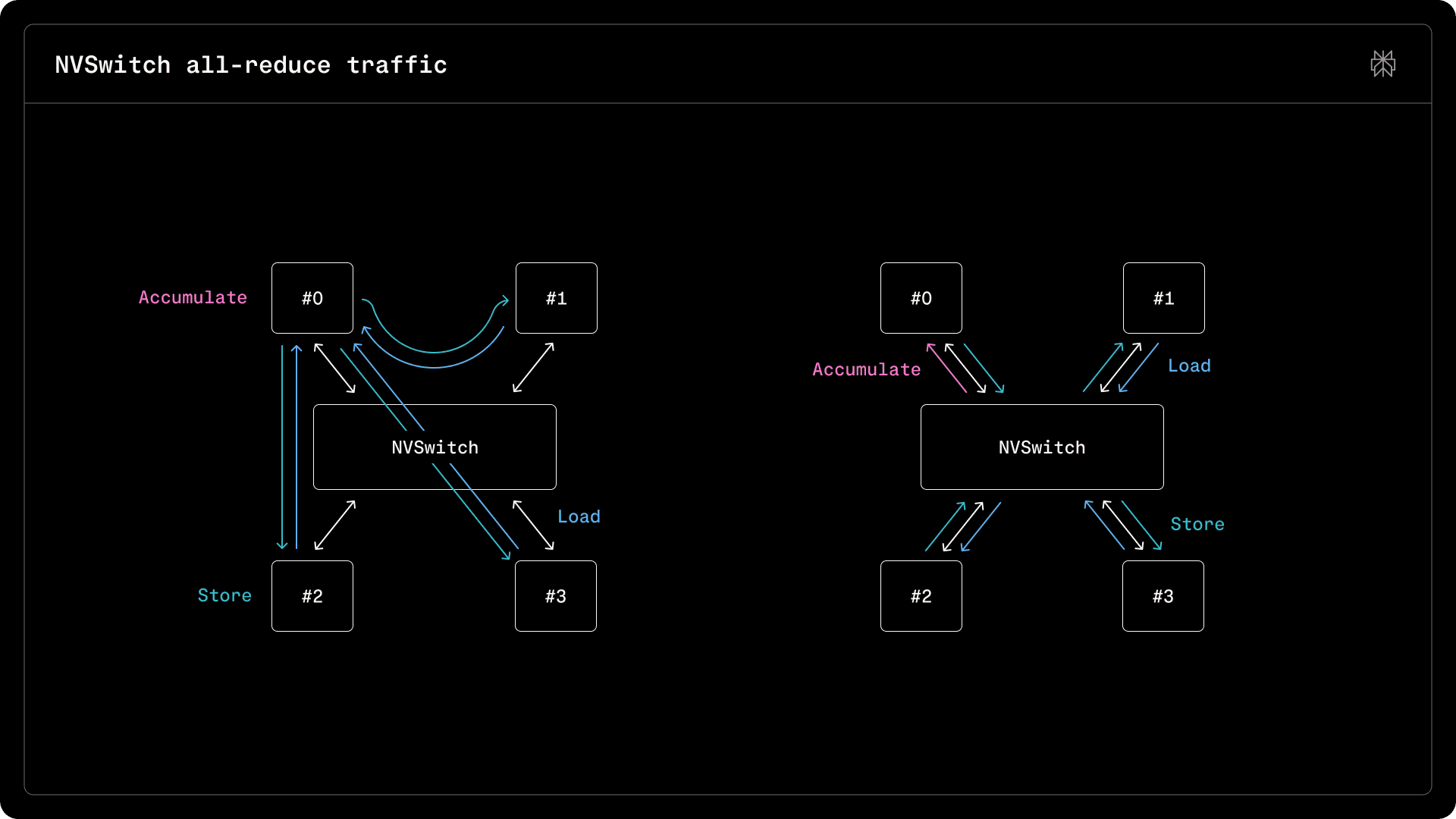
With SHARP, the reduction and the broadcast can be performed more efficiently: instead of reading in (N - 1) * (B / N) bytes into a device for local accumulation, only B / N are moved from the switch, as it performs the reduction itself using data from the peers. For broadcast, there is a similar improvement, as the number of transactions between a GPU and the switch over NVLink channels is greatly reduced. Without SHARP, the accumulating device would perform (N - 1) * (B / N) transactions over NVLink with the switch, with the switch reading the same amount of data from the peers, for a total of 2 * (N - 1) * (B / N) transactions. With SHARP, B / N transactions are performed between the GPU and the switch, and a further (N - 1) * (B / N) with the peers, for a total of B transactions.
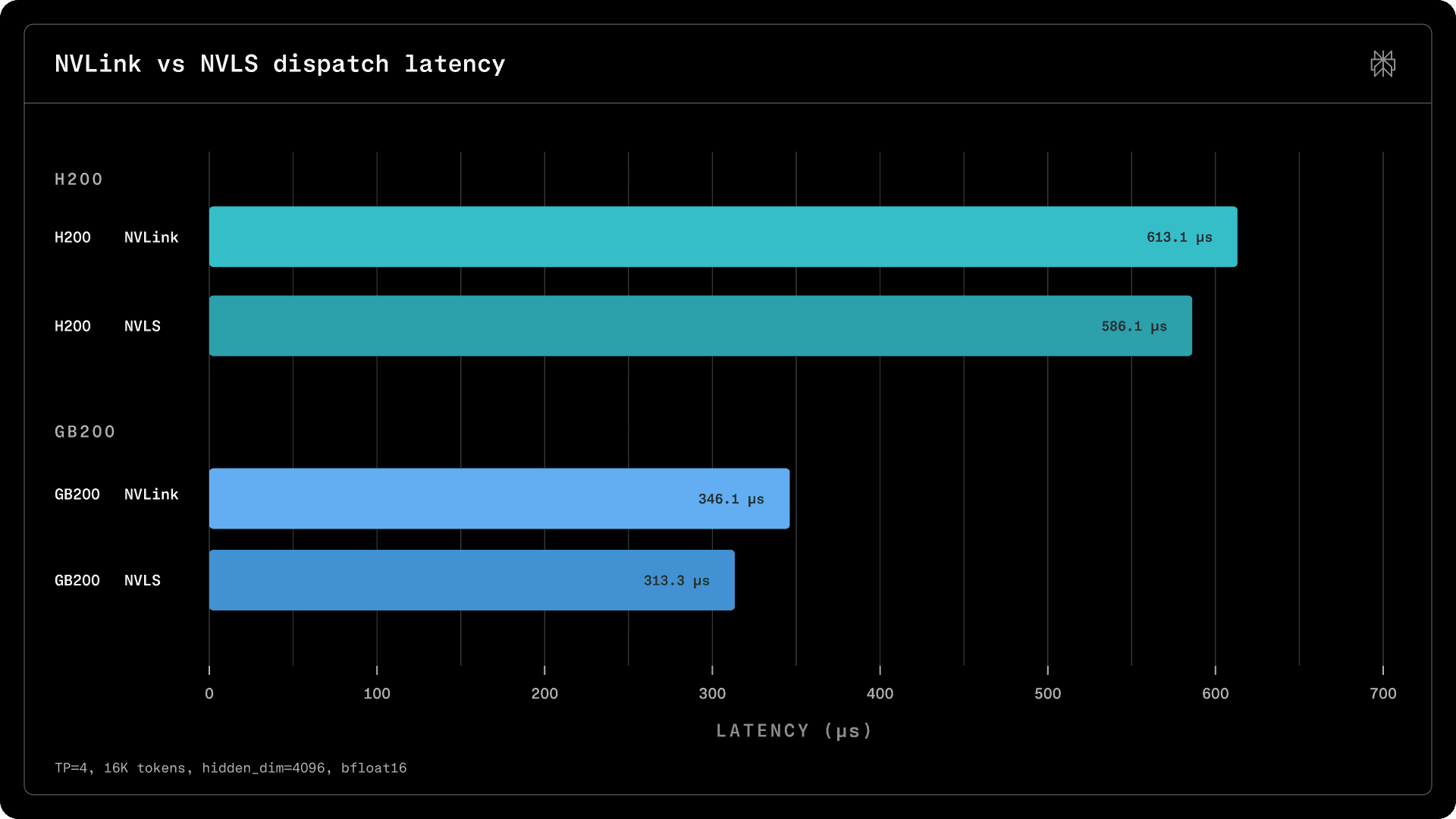
Due to its simplicity, SHARP is a valuable tool, as it provides a straightforward hardware implementation for an algorithm. Even though the transfers are reduced by a theoretical N / (2 * (N - 1)) fraction (which evaluates to 33% with 4 peers), in practice we observe a 10% improvement in both prefill and decode latencies on both H200 and GB200 NVL72 systems.
MoE Dispatch - Combine
For MoE models, dispatch and combine kernels move and group tokens for the subsequent MoE GEMM problems between peers, performing a weighted accumulation afterwards in combine. We have adapted our existing Dispatch and Combine kernels to Blackwell, by porting them to CuTeDSL, tweaking the block allocations and aggressively specializing them between prefill and decode.
Expert Parallel
The expert parallel (EP) kernel is used in prefillers. Since its inputs are replicated across all ranks, the dispatch kernel needs to simply select the tokens routed to experts on the current rank. It aggregates routing information and prepares tokens into buffers used as inputs to MoE GEMM. The combine kernel first performs a local accumulation between the contributions of tokens routed to experts on the current rank, then it performs an all-reduce across all ranks.
For decode, the whole kernel is fused into one. The prefill kernel is split into multiple kernels, as routing and all-reduce require fewer blocks than the local combine step. With CuTeDSL, we could build a generic library for both SHARP and NVLink all-reduce and peer-to-peer synchronization, composing it into both the all-reduce and the expert parallel kernels.
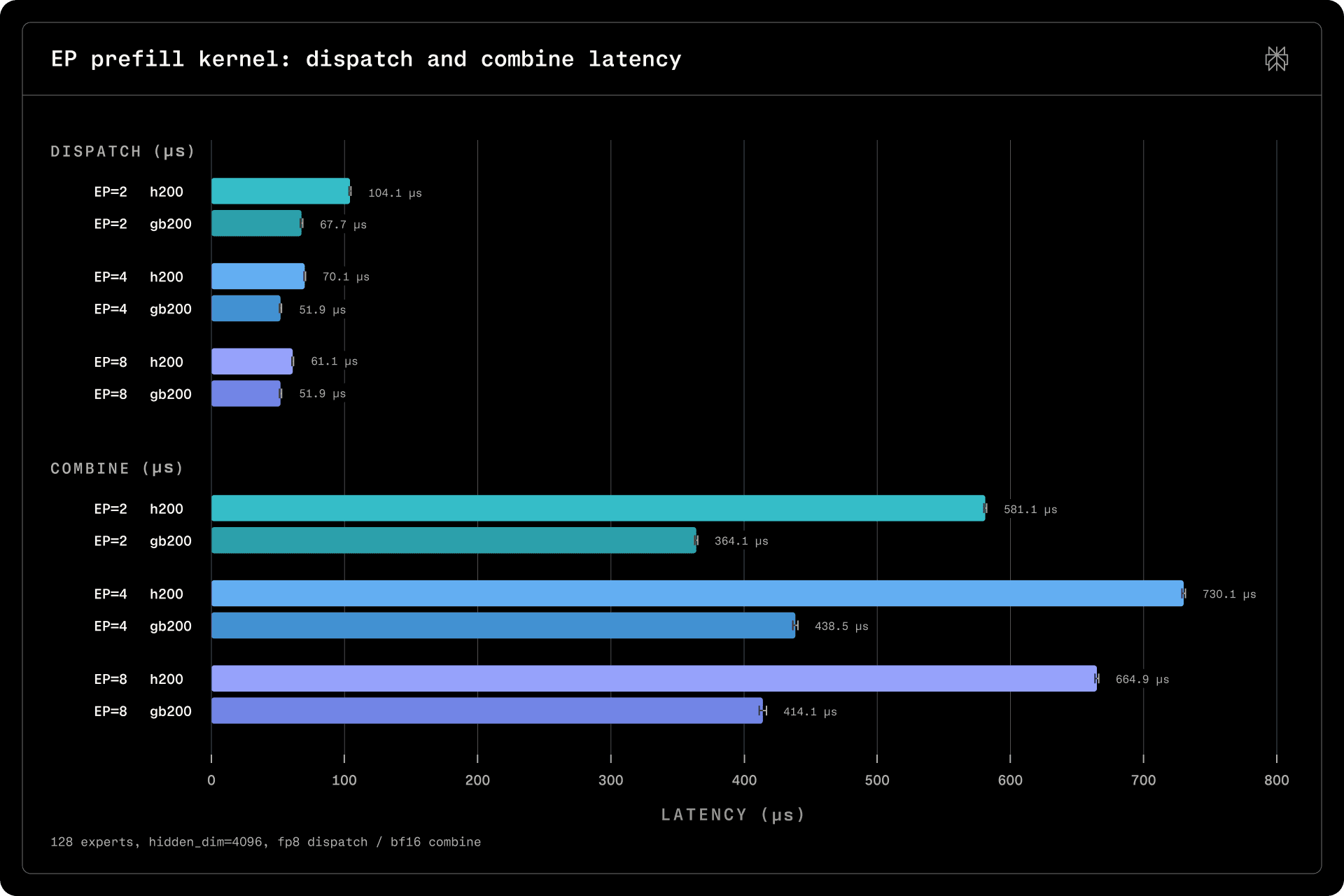
Performance-wise, we observe that Blackwell is substantially faster than Hopper, due to improved transfer speeds, higher memory bandwidth, and better computational throughput. Sharded across 8 devices and multiple nodes on GB200s (EP=8), the kernels become faster as the local accumulation runs on much fewer tokens on each device and, with SHARP, the cost of reduction across more ranks scales better. However, in practice, we limit parallelism to 4 devices, as these speedups are not universal across all kernels.
Data Parallel and Expert Parallel
The data parallel and expert parallel (DP-EP) kernel is used in the data parallel decoders. It broadcasts different tokens from all ranks to experts, transferring the results to the originating ranks and accumulating them. Since it implements a sparse all-to-all problem, it relies solely on NVLink.
On Hopper, this kernel is limited to 8 devices within the NVLink domain of a single node. However, on GB200 systems we can scale it across an entire rack. Most of the code is reused. The only difference is the use of fabric handles to exchange peer information over IMEX for the initial setup.
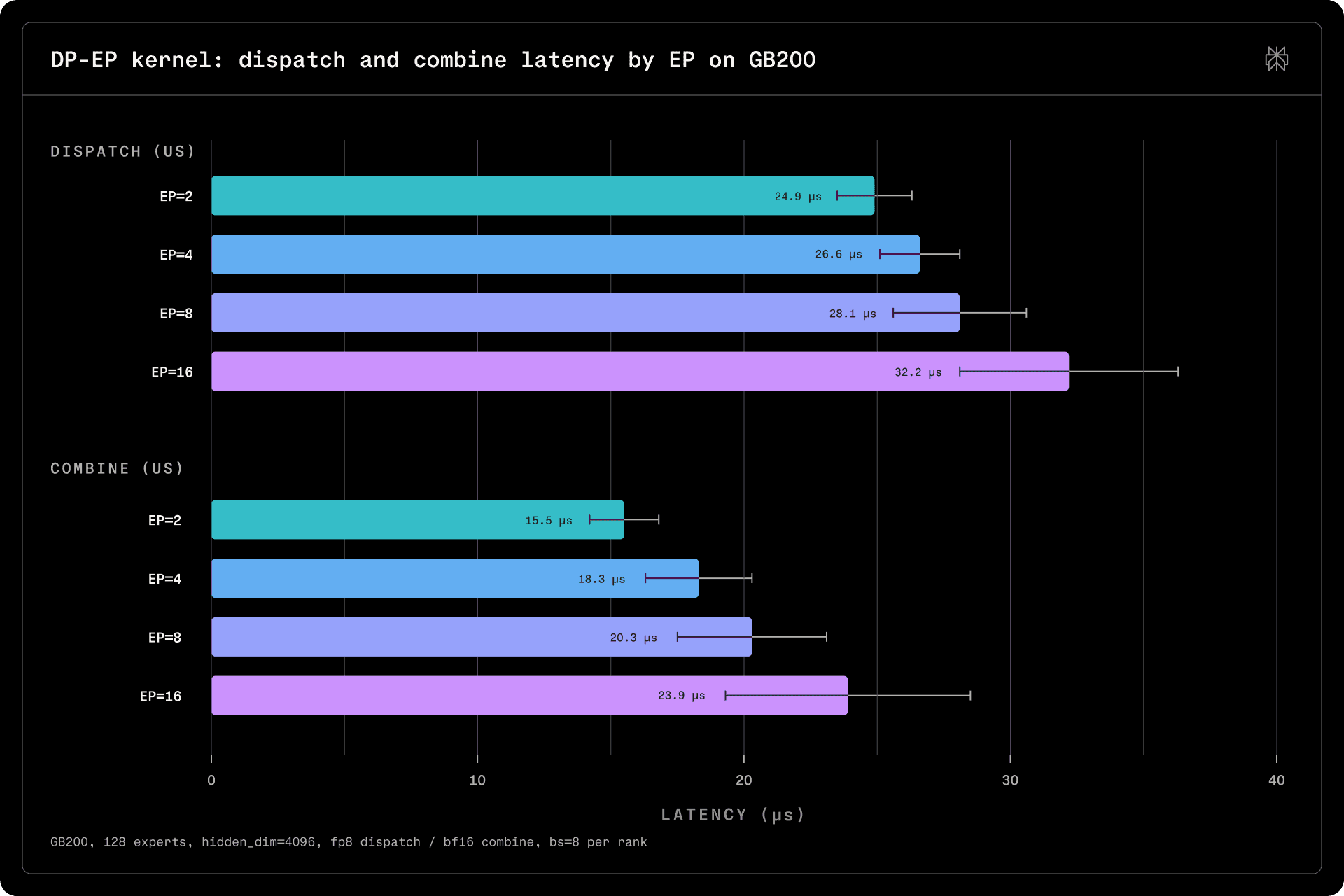
Since the transfer sizes incurred during decode are small, they are far from saturating NVLink bandwidth and are instead latency-limited. Latencies are in the tens of microseconds and remain relatively stable as the number of peers increases, allowing us to spread a deployment across a larger number of devices without incurring significant additional latency.
MoE GEMM
MoE models benefit from expert parallelism, as the cost of multiplying all tokens with all experts can be easily parallelized across multiple devices. With tensor parallelism on prefillers, on dense problems the benefit is quite straightforward, as each rank now has to perform fewer computations. In the decode case, data parallelism provides an additional benefit on top of expert parallelism, as the larger number of parallel requests routes more tokens to each expert, densifying the problems.
In our implementation, we presently rely on CUTLASS CUDA/C++ kernels for matrix multiplication. We benchmarked them on sparse decode inputs with various quantization schemes and levels of parallelism in order to decide the optimal sharding strategy for decoders. In the benchmarks below, all experts are activated with a single token.
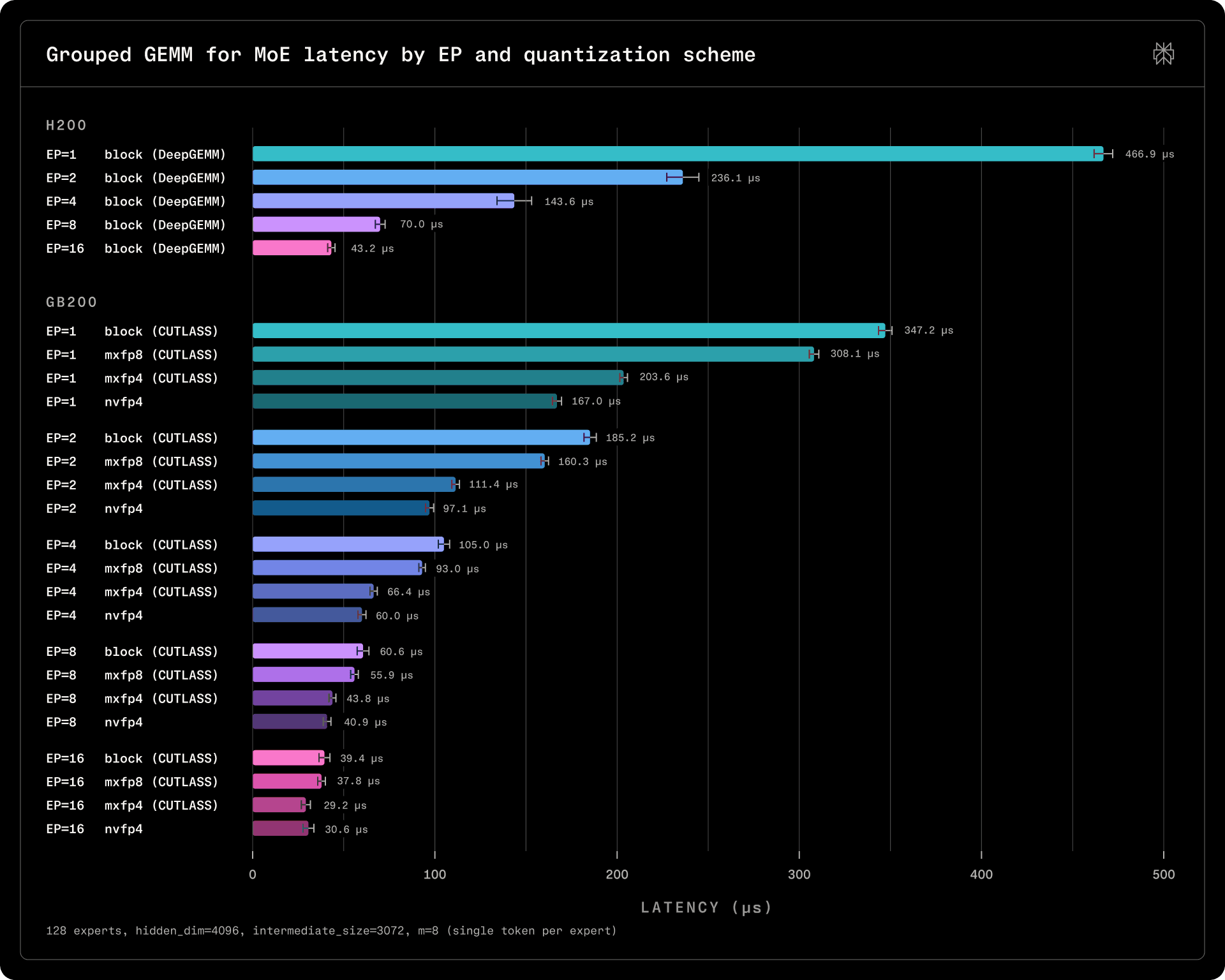
We found that scaling 128 experts across more than 16 ranks yields diminishing returns with CUTLASS, as the cost of multiplying 2 experts is not substantially lower than multiplying 4. There is a clear improvement on Blackwell over Hopper, even on the sub-optimal block scaling strategy. Since the latency increase of about 5 us between EP=8 and EP=16 of dispatch/combine is outweighed by a decrease of more than 10 us in the cost of GEMM, on GB200 systems, sharding decoders across 16 ranks is justified, as confirmed by end-to-end benchmarks as well.
Quantization
Blackwell introduces hardware support for new 8-bit and 4-bit quantization schemes. Unlike Hopper, which relied on per-tensor or per-block scaling scaling factors, Blackwell requires microscaling to achieve the best prefill and decode throughput. While the block scaling scheme used for models such as DeepSeek or Kimi is available, microscaling is more efficient.
We have deployed Qwen3 235B with the MXFP8 quantization scheme, converting the weights statically after fine-tuning the model. The accuracy impact was similar to the impact of block scaling with stochastic quantization, but the performance delivered was much improved, as illustrated by the MoE GEMM microbenchmarks. We have also considered the MXFP4 and NVFP4 quantization schemes, although the accuracy impact without Quantization-Aware Training was too significant for the initial transition from Hopper to Blackwell. We plan to explore these formats more thoroughly in future work.
End-to-End performance
We benchmarked the decoders of Blackwell Qwen3 235B deployments and compared them to our previous Hopper deployments. In this setup, we considered block scaling across both deployments in order to focus on the impact of parallelism. TP=4 prefillers were separated for both architectures in order to isolate the decode performance. The figure below illustrates decoding throughput assuming a realistic draft acceptance rate delivered by our MTP layers.
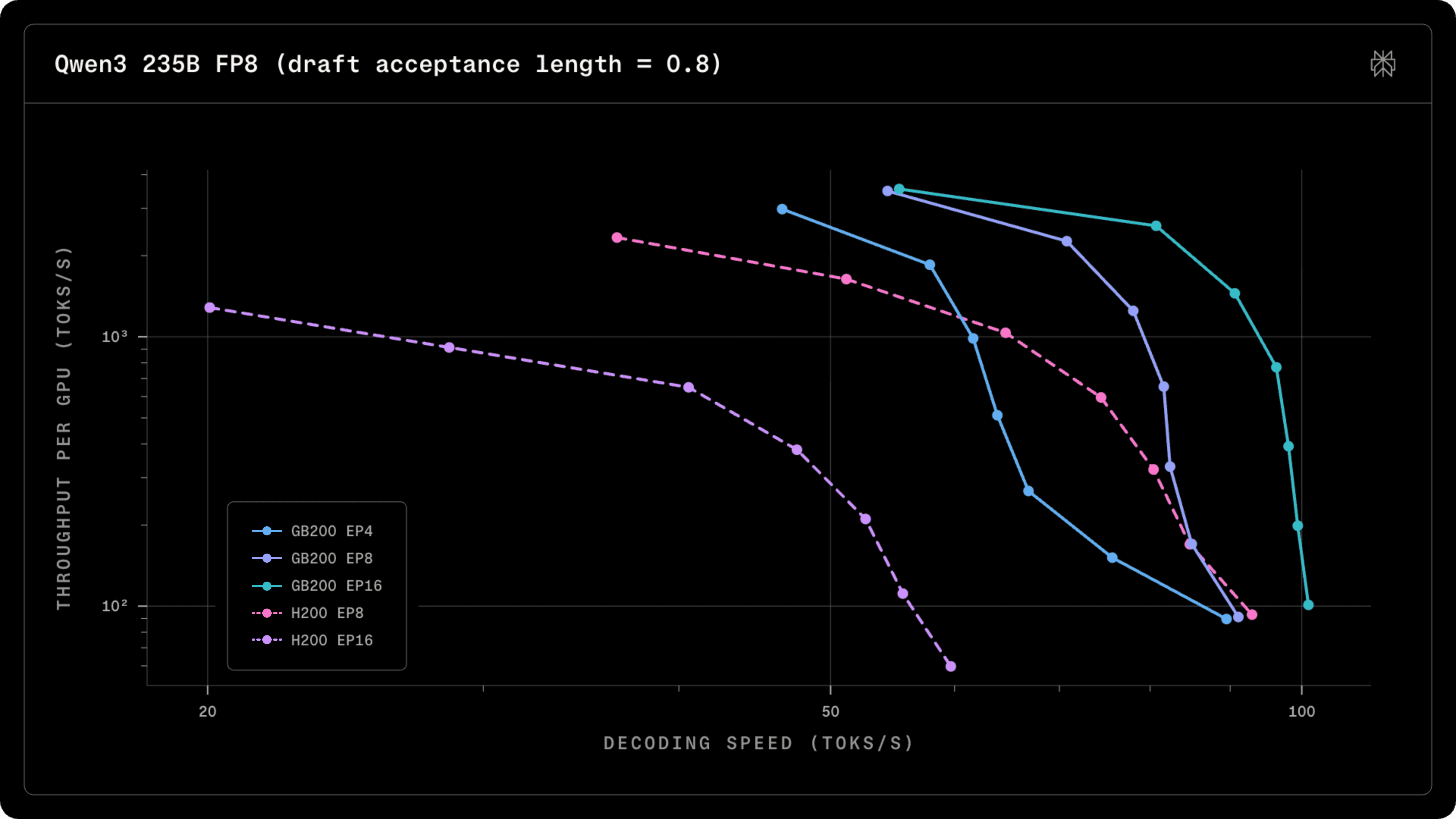
On Hopper, sharding the deployment across more than 8 GPUs is not viable, as the latencies across InfiniBand, particularly on EFA adapters, are substantially slower. However, on Blackwell, we achieve substantially higher throughput, thanks to the larger NVLink domains.
We achieved an initial Blackwell implementation by generalizing existing Hopper kernels and pushing the performance of the NVLink-based kernels. We will be further reducing the cost of serving Qwen by improving quantization and fine-tuning the decode performance and prefill throughput of the other kernels in the pipeline.